반응형
나와 제일 가까운 의료 기관 데이터 분석 및 지도 시각화
라이브러리 임포트
import pandas as pd
import plotly.express as px한글 깨짐 방지
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()데이터 준비하기
df = pd.read_csv('/content/data.csv', encoding='EUC-KR')
df.head()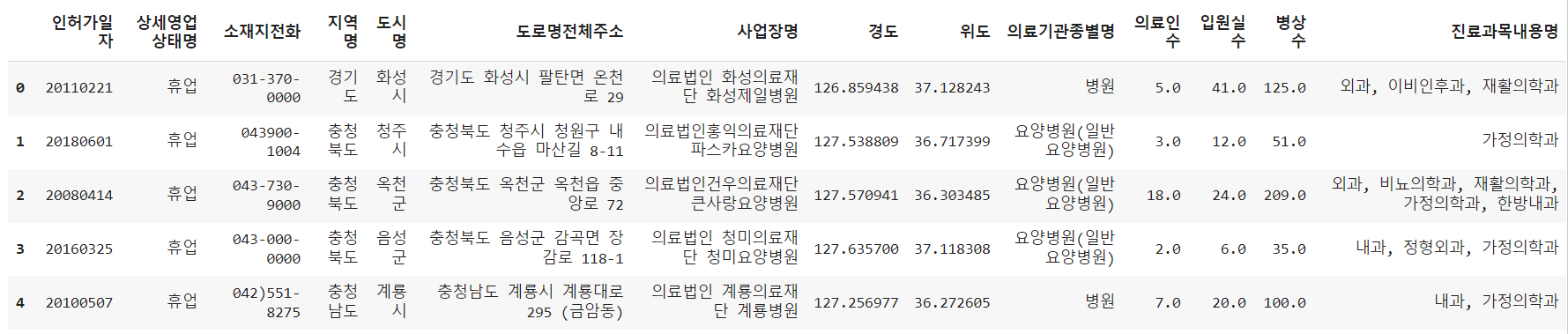
: 데이터 확인하기 (머신러닝, 딥러닝할때 무조건 확인해야함.) 데이터 분석할때 역시 어떤 부분에서 분석할 수 있는가를 찾기 위해 해보는 것이 좋음.
df.info()
NAN 데이터 확인하기
df.isna().sum()
컬럼별 데이터 확인
df.상세영업상태명.unique()
df.지역명.unique()
df.의료기관종별명.unique()
데이터 분석하기
상세 영업 상태 별 의료 기관 수
df['상세영업상태명'].value_counts()
gb_df = df.groupby(by=['상세영업상태명']).size().reset_index(name='의료기관수')
gb_df
- histogram 차트
px.histogram(gb_df, x='상세영업상태명', y='의료기관수')
- pie 차트
px.pie(gb_df, names='상세영업상태명', values='의료기관수')
- 여기서 잠깐! 폐업인 곳이 너무 많다 그 이유가 뭘까? ==> 우선, COVID-19로 인해서 병원도 폐업한 곳이 많았다고 함. 또한, 이 데이터에 포함된 병원이 언제부터 영업한 병원들일까? 이 데이터가 인허가일자가 가장 빨랐던 곳이 어디인지 궁금해지니까 한번 분석해보자.
df['인허가일자'].max()
df['인허가일자'].min()
: 위의 코드의 출력결과에서 보이는 것과 같이, 인허가날짜가 1900년부터 된 병원이 포함되어 있는 것을 보니, 그 후부터 폐업한 병원들 모두 누적된 결과 28%에 육박하는 수치가 나온 것이라고 판단해볼 수 있을 것이다.
지역별 의료 기관 수
df['지역명'].value_counts()
lgb_df = df.groupby(by=['지역명', '도시명', '상세영업상태명','의료기관종별명']).size().reset_index(name='의료기관수')
lgb_df
- histogram 차트
px.histogram(lgb_df, x='지역명', y='의료기관수')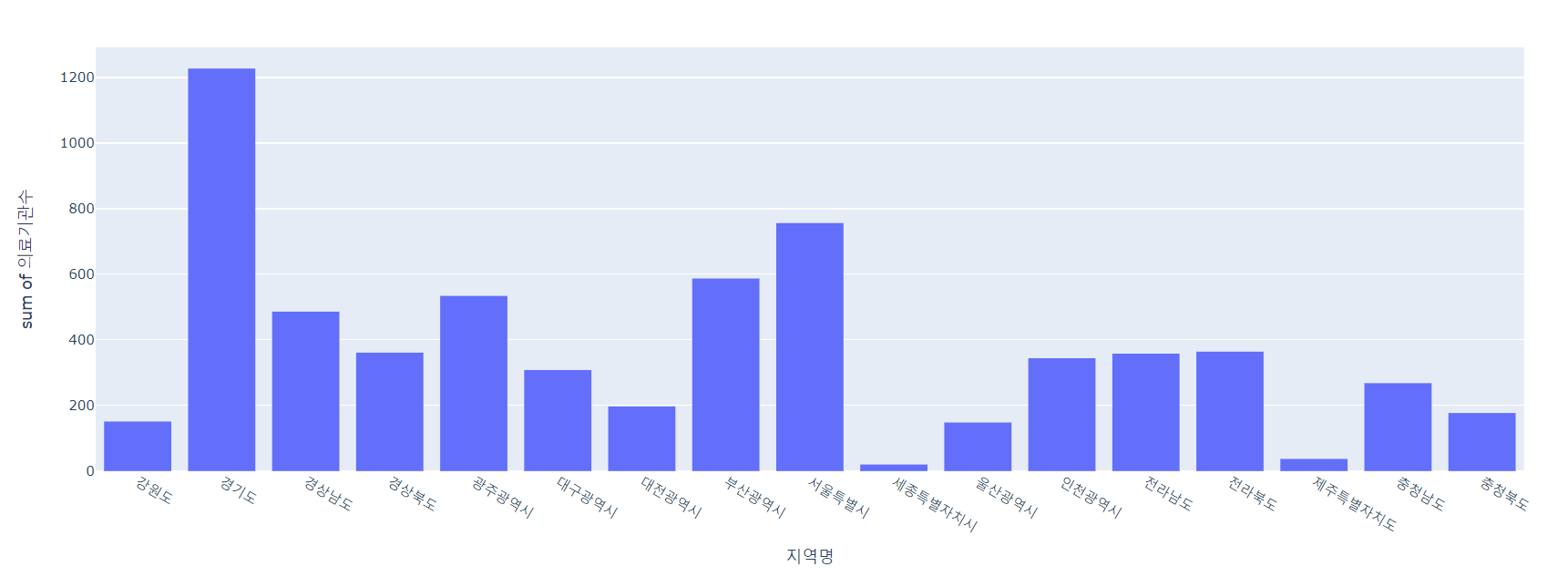
: 경기도 데이터만 따로 봐보자. 데이터 수가 1227로 나오는데 실제 데이터는 1237건이다. 왜 절게 나왔을까? ==> 널 데이터는 제외하고 나왔음!
px.histogram(lgb_df, x='지역명', y='의료기관수', color='상세영업상태명')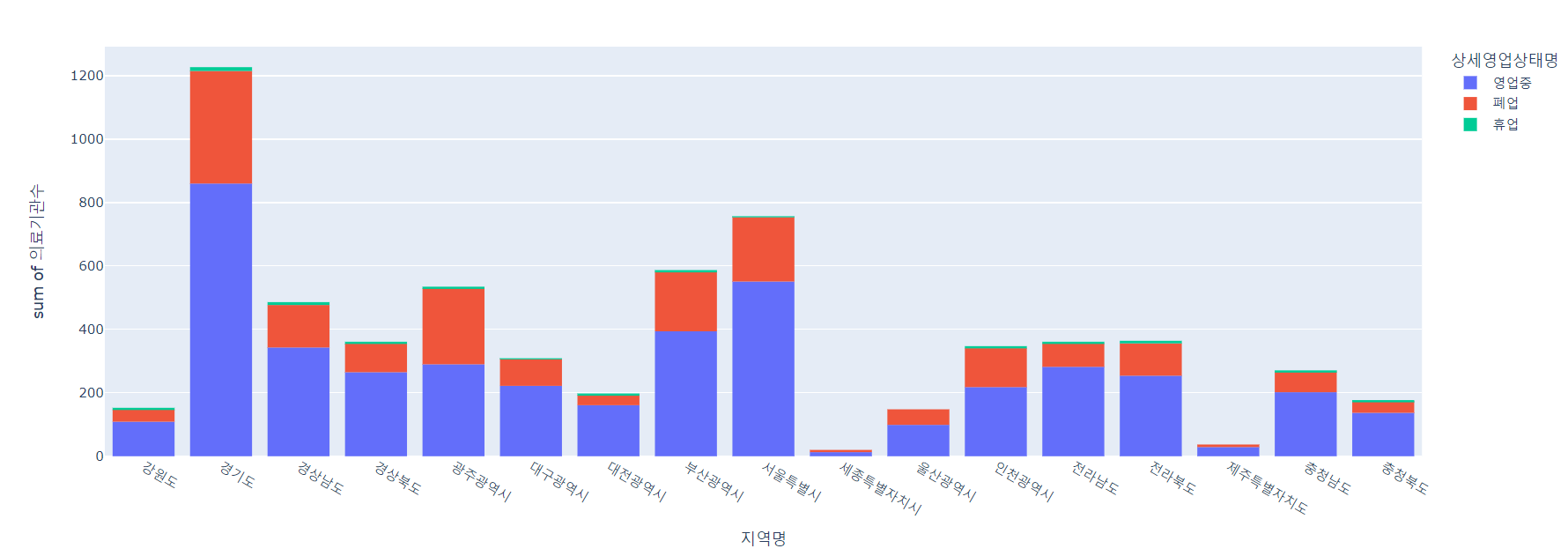
px.histogram(lgb_df, x='지역명', y='의료기관수', color='도시명')
- pie 차트
px.pie(lgb_df, names='지역명', values='의료기관수')
의료 기관종 별 의료 기관 현황
- histogram 차트
px.histogram(lgb_df, x='의료기관종별명', y='의료기관수')
- pie 차트
px.pie(lgb_df, names='의료기관종별명', values='의료기관수')
워드 클라우드 시각화
진료과목에 대한 워드 클라우드
- 라이브러리 임포트
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator- 진료과목 명을 하나의 텍스트 형태로 변환
text = " ".join(cont for cont in df.진료과목내용명.astype((str)))- 텍스트 데이터의 개수를 판단해보자.
print('총 {}개 문자열 데이터가 있습니다.'.format(len(text))) # 이건 text의 문자열의 길이(데이터의 개수가 아님!)
==> 이건 text 문자열 자체의 길이지 데이터의 개수가 아님. 데이터의 개수를 알려면 어떻게 해야 할까?
print('총 {}개 문자열 데이터가 있습니다.'.format(len(text.split(' '))))
==> 공백을 기준으로 나누면 그게 바로 데이터의 개수라고 할 수 있다!!!
plt.subplots(figsize=(25, 14))
wordcloud = WordCloud(background_color='white', width=1000, height=700, font_path=fontpath).generate(text) # 여기서 fontpath는 위의 한글깨짐방지 코드에서 선언해줌.
plt.axis('off')
plt.imshow(wordcloud, interpolation='bilinear') # interplation은 간격 조정
plt.show()
LIST
'대외활동 > ABC 지역주도형 청년 취업역량강화 ESG 지원산업' 카테고리의 다른 글
| [ABC 220906 - 16일차] 오후 실습 과제 (1) | 2022.09.11 |
|---|---|
| [ABC 220906 - 16일차] 오전 실습 과제 (0) | 2022.09.11 |
| [ABC 220905 15일차] - 과제 실습 (0) | 2022.09.11 |
| [ABC 220905 15일차] - 나와 제일 가까운 무료 WIFI는 어디 있을까? (1) | 2022.09.10 |
| [ABC 220902 14일차] - 6번째 특강 (0) | 2022.09.05 |



