분류와 회귀
- 지도 학습에는 답이 있다는 것이 특징!
- 지도 학습에는 분류(Classification)와 회귀(Regression)가 있음
- 분류 (Classification) : 분류는 미리 정의된, 가능성 있는 여러 클래스 레이블(class label) 중 하나를 예측하는 것
- 딱 두개의 클래스로 분류하는 이진 분류(binary classification)
- 이진 분류는 질문의 답이 예/아니오만 나올 수 있도록 하는 것
- 이메일에서 스팸을 분류하는 것이 이진 분류 문제 → 예/아니오 대답에 대한 질문은 "이 메일은 스팸인가요?"
- 이진 분류에서 한 클래스를 양성(pasitive) 클래스 (좋은 값이나 장접을 나타내는 것이 아니라 학습하고자 하는 대상) 다른 클래스를 음성(negative) 클래스
- 셋 이상의 클래스로 분류하는 다중 분류 (multiclass classification)
- 붓꽃의 분류 ( 붓꽃이 종류가 여러개), 웹사이트의 글로부터 어떤 언어의 웹사이트인지를 예측(한국어 or 영어 or 일본어 등)
- 시험지 : X, 독립변수, Feature, Data
- 정답지 : y, class , 레이블, 종속변수, Target
- 딱 두개의 클래스로 분류하는 이진 분류(binary classification)
- 회귀 : 연속적인 숫자, 또는 프로그래밍 용어로 말하면 부동소수점수(수학 용어로는 실수)를 예측하는 것 - 주식, 집값, 관객 수 등
- 어떤 사람의 교육 수준, 나이, 주거지를 바탕으로 연간 소득을 예측
- 옥수수 농장에서 전년도 수확량과 날씨, 고용 인원 수 등으로 올해 수확량을 예측
- 출력값에 연속성이 있는지 질문해보면 회귀와 분류 문제를 쉽게 구분할 수 있음
- 출력값 사이에 연속성이 있다면 회귀 문제, 연속성이 없으면 분류 문제
- 출력값이란 y값(class, 레이블, 종속변수, target)을 말함
머신러닝 실습 : Iris 품종 분류
- 어떤 품종인지 구분 해놓은 측정 데이터를 이용해 새로 채집한 붓꽃의 품종을 예측하는 머신러닝 모델 만들어보기
- 데이터 적재
- 성과 측정 : 훈련 데이터와 테스트 데이터
- 가장 먼저 할 일 : 데이터 살펴보기
- 첫번째 머신러닝 모델 : k-최근접 이웃 알고리즘
- 예측하기
- 모델 평가하기
- ndarray : 다차원 배열. numpy에서 제공하는 자료구조. 다차원 배열 수준의 연산이 가능함. 수학적으로 계산이 가능하거나, 차원을 수축을 위해 사용하는 numpy가 제공해주는 라이브러리
- 문제 정의 : 붓꽃의 품종을 분류 → 3개의 품종 중 하나를 예측하는 다중 분류 문제로 정의
- 문제집 → 데이터 특성(feature), 독립변수(x) : 꽃잎, 꽃받침의 길이(cm) 4가지
- 정답 → 클래스(class), 레이블(label), 타깃(target), 종속변수(y) : 붓꽃의 품종(setosa, versicolor, vriginica)
데이터 준비하기
from sklearn.datasets import load_iris
iris_dataset = load_iris()데이터 확인하기
iris_dataset['target'] #정답지, label 확인
iris_dataset['data'] # 문제집, feature 확인
type(iris_dataset['target'])
iris_dataset['target'].shape
# 앞이 데이터의 수, 뒤가 몇차원 배열인지 아무것도 없으면 1차원 배열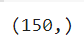
iris_dataset['data'].shape
import matplotlib.pyplot as plt
import pandas as pd
# 데이터 프레임을 사용하여 데이터 분석 -> feature 와 label 의 연관성을 확인
iris_df = pd.DataFrame(iris_dataset['data'], columns=iris_dataset.feature_names)
iris_df.head()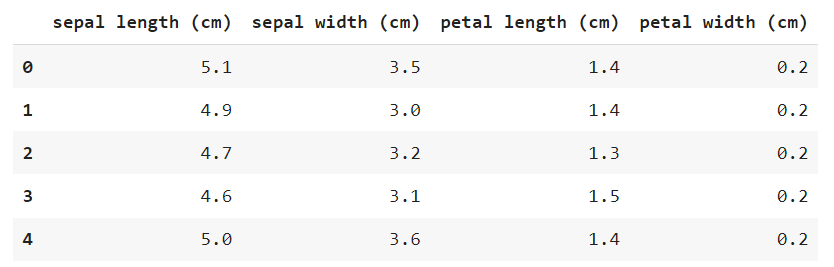
iris_df.info()
각 feature 들의 산점도 행렬 4X4
- 산점도를 그려봤을 때 몰려있지 않고 shift되어 있으면 구분이 잘 되어 있다는 의미
pd.plotting.scatter_matrix(iris_df, c=iris_dataset['target'], figsize=(15,15),
marker='o', hist_kwds={'bins':20}, s=60, alpha=.8)
plt.show()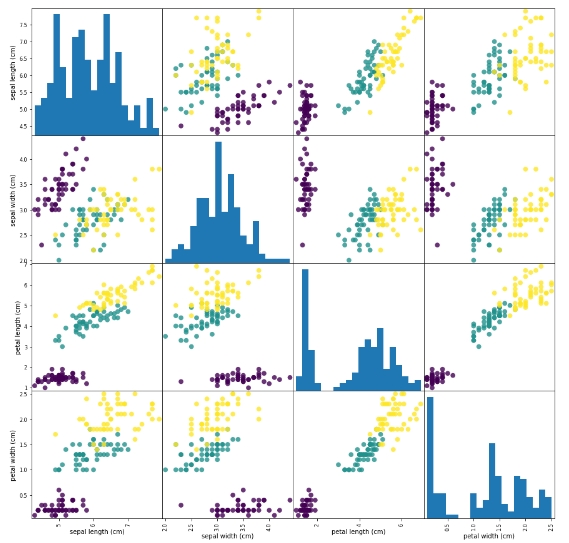
import numpy as np
plt.imshow([np.unique(iris_dataset['target'])])
_ = plt.xticks(ticks=np.unique(iris_dataset['target']), labels=iris_dataset['target_names'])
※ _ 언더스코어 : 변수를 안쓰고 싶은데 안쓰면 안될 때 사용함. 굳이 변수에 담지 않아도 출력해줌 변수를 안쓰고 싶은데 변수에 담아야할 때 사용
df2에 자신이 원하는 담고 싶은 컬럼들만 담자
iris_df2 = iris_df[['petal length (cm)','petal width (cm)']]
iris_df2.info()pd.plotting.scatter_matrix(iris_df2, c=iris_dataset['target'], figsize=(10,10),
marker='o', hist_kwds={'bins':20}, s=60, alpha=.8)
plt.show()훈련 데이터와 테스트 데이터 분리
# 훈련 데이터, 테스트 데이터 -> 70:30 OR 85:15 OR 80:20 OR 90:10 정도의 비율로 나눔
from sklearn.model_selection import train_test_split
# x는 여러개의 feature로 구성된 학습데이터가 들어있기 때문에 대문자로 표현!
# 순서 틀리면 난리난다.
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'],
test_size=0.25, random_state=777)
# random_state는 random seed를 고정해줌 해당 숫자를 기준으로 자른다
# random할 때 자르고 나서 고정된 seed로 같은 위치로 해야 모델의 성능에 정확성을 판단하고자 함.# 훈련 데이터 확인하기 150 => 75% => 112개
X_train.shape
# 테스트 데이터 확인하기 150 -> 25% -> 38개
X_test.shape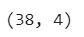
y_test
머신러닝 모델 설정 → k-최근접 이웃 알고리즘
from sklearn.neighbors import KNeighborsClassifier
# neighbors = 1 여기서 1을 조정해서 정확도를 조절해보는 것(파라미터 조정)
knn = KNeighborsClassifier(n_neighbors=1) # 이웃의 개수를 1개로 지정 (가장 가까이 있는 이웃을 보고 판단을 하겠다)학습하기
knn.fit(X_train, y_train)
# .fit()
예측하기
y_pred = knn.predict(X_test)
y_pred
모델 평가하기 (정확도 확인)
1) mean() 함수를 사용해서 정확도를 확인하기
np.mean(y_pred == y_test)
2) score() 함수를 사용해서 정확도 확인하기 → 테스트 셋으로 예측한 후 정확도를 출력
knn.score(X_test, y_test)
3) 평가 지표 계산
from sklearn import metrics
knn_report = metrics.classification_report(y_test, y_pred)
print(knn_report)
머신러닝 실습 : 지도 학습 분류와 회귀 데이터셋 확인
mglearn 라이브러리 설치
pip install mglearn한글 깨짐 방지 코드
# 한글폰트 패치
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()예제에 사용할 데이터 셋
1. 이진 분류 데이터셋(forge) 확인하기 (가상의 데이터)
import mglearn
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# 데이터셋 다운로드
X , y = mglearn.datasets.make_forge()데이터 확인하기
print("X.shape : ", X.shape)
print("y.shape : ", y.shape)
plt.figure(dpi = 100)
plt.rc('font', family='NanumBarunGothic')
# 산점도 그리기
mglearn.discrete_scatter(X[:,0], X[:,1], y)
# x1 feature와 x2 feature의 중간지점이 scatter로 찍힘
plt.legend(['클래스 0', '클래스 1'], loc = 4)
plt.xlabel("첫 번째 특성")
plt.ylabel("두 번째 특성")
plt.show()
2. 회귀 데이터셋 (wave) 확인하기
X, y = mglearn.datasets.make_wave(n_samples=40)
# 너무 데이터셋이 많아지면 헷갈리니까 40개의 데이터로만 확인해보자데이터 확인하기
print("X.shape : ", X.shape)
print("y.shape : ", y.shape)
y
# 연속적인 숫자? -> 회귀모델임.
# 산점도 그리기 X, y에 대해서 그리기
plt.figure(dpi=100)
plt.rc('font', family='NanumBarunGothic')
plt.rcParams['axes.unicode_minus'] = False
plt.plot(X, y, 'o')
plt.ylim(-3, 3)
plt.xlabel('특성')
plt.ylabel('타깃')
plt.show()
분류 문제 정의 : 위스콘신 유방암 데이터셋을 사용한 악성 종양(label 1) 예측하기
원본 출처 = https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Diagnostic%29
UCI Machine Learning Repository: Breast Cancer Wisconsin (Diagnostic) Data Set
Breast Cancer Wisconsin (Diagnostic) Data Set Download: Data Folder, Data Set Description Abstract: Diagnostic Wisconsin Breast Cancer Database Data Set Characteristics: Multivariate Number of Instances: 569 Area: Life Attribute Characteristics: Real N
archive.ics.uci.edu
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()cancer['target_names']
# malignant : 악성
# benign : 양성
cancer['target']
# 이진 분류할 때 Tip! : 내가 찾을 target label을 무조건 1로 인식
# 즉, 우리는 악성종양을 찾아야 하기 때문에 1로 코딩해줘야한다!
# 이런 인코딩은 우리가 바꾸는 것!
# 여기서는 0 : 악성, 1 : 양성
cancer['data'].shape
# 569건의 데이터 수와 30의 특성으로 이루어진 dataset
cancer.feature_names
import pandas as pd
df = pd.DataFrame(cancer['data'], columns=cancer.feature_names)
pd.plotting.scatter_matrix(df, c = cancer['target'], figsize=(15,15),
marker='o', hist_kwds={'bins':20}, s=10, alpha=.8)
plt.show()
import numpy as np
plt.imshow([np.unique(cancer['target'])])
_ = plt.xticks(ticks=np.unique(cancer['target']), labels=cancer['target_names'])
'대외활동 > ABC 지역주도형 청년 취업역량강화 ESG 지원산업' 카테고리의 다른 글
| [ABC 220921] 지도 학습 알고리즘 k-NN 알고리즘 (1) | 2022.10.17 |
|---|---|
| [ABC 2200920] 지도 학습 알고리즘 - 일반화, 과대적합, 과소적합 (0) | 2022.10.01 |
| [ABC 220919] 머신러닝 프로세스 (1) | 2022.09.27 |
| [ABC 220919] 인공지능(AI), 머신러닝, 딥러닝 소개 (1) | 2022.09.23 |
| [ABC 220913 ~ 220919] First Project (0) | 2022.09.23 |


