교통사고 현황 데이터 분석
1. 라이브러리 임포트
import pandas as pd
import plotly.express as px2. 데이터 준비하기
- 데이터를 불러오기 전에, 데이터를 먼저 확인해보자.

왜 notepad++로 열었냐? => 데이터의 개수가 많은 csv 파일일 경우에는 엑셀로 열게 되면 데이터가 깨질 수 있다. notepad++로 열면 안깨짐!!
데이터를 열어서 우리가 확인할 것? - 1. encoding 방식 확인, 2. 데이터 개수 확인, 3. 각 데이터 형식 확인
- 데이터 불러오기
df = pd.read_csv('/content/도로교통공단_교통사고 정보.csv', encoding='euc-kr')
df.head()
: 이때, 왜 경로가 내 PC가 아닐까? ==> Colab에 직접 데이터 csv 파일을 추가해서 불러오는 것이기 때문. 그냥 업로드된 파일에 마우스 오른쪽 버튼 누르고 경로복사해서 해주면 됨.
- 불러왔으면 확인하자
df.info()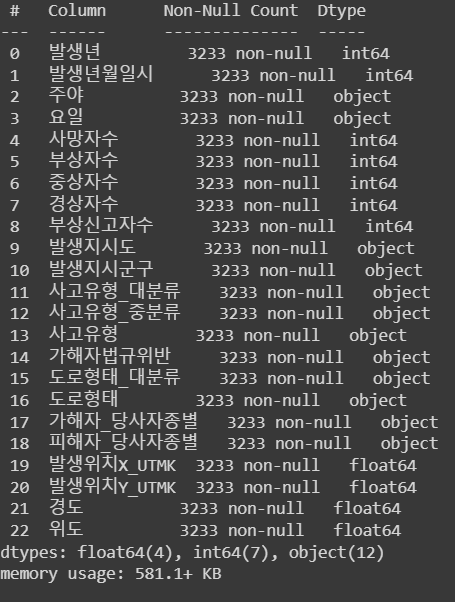
위의 단계까지 실행한 뒤에 데이터 분석을 시작하자
1) 데이터가 제대로 불려왔는지, column들도 확인하기
2) 이 데이터의 핵심은 위도와 경도가 존재한다는 것! ==> 지도 시각화가 가능하다.
3) 각 column의 dtype을 확인하자
3. 교통사고 데이터 전처리
- 데이터를 처리할 때 가장 중요한 것은 null(널) 데이터와 날짜 데이터임.
- 발생년월일시 → 2019 01 01 00(int) → 발생년월일(datetime), 뒤에 두자리 (시간)을 따로 컬럼으로 분리한다.
- 이 데이터를 갖고 시간대별 교통사고 현황을 분석할 수 있음.
1) 발생년월일시 연속적인 숫자(int) → string(문자열) 자료형으로 자를 수 있는 형태로 변경하자.
2) 뒤에 두자리를 발생시간 column으로 int 타입으로 바꿔주자.
3) 앞자리는 발생년월일 column으로 Datetime 타입으로 바꿔주자.
1) 발생년월일시 연속적인 숫자(int) → string(문자열) 자료형으로 자를 수 있는 형태로 변경하자.
df = df.astype({'발생년월일시':'string'})
df.info()

2) 발생년월일시 → 뒤에 두자리(시간) 자르고 발생시간이라는 칼럼에 담자
ex) 2019010100 → 00 시간으로 분리
df['발생시간'] = df['발생년월일시'].str[8:]3) 발생시간을 숫자 데이터타입으로 변경하자
df = df.astype({'발생시간' : 'int64'})
df.info()
4) 발생년월일시(string) → 날짜 타입으로 변경
ex) 2019010100 → 20190101(년월일) → 2019-01-01 (날짜형태 YYYY-MM-DD)
df['발생년월일시'] = pd.to_datetime(df['발생년월일시'].str[:8], format='%Y-%m-%d', errors = 'raise')
df.info()
4. 지역별 / 시간대별 교통사고 현황 보기
- 날짜와 시간, 지역별의 연관성을 확인하기 위한 차트
fig = px.scatter(df, x='발생년월일시', y='발생시간', color='발생지시도')
fig.show()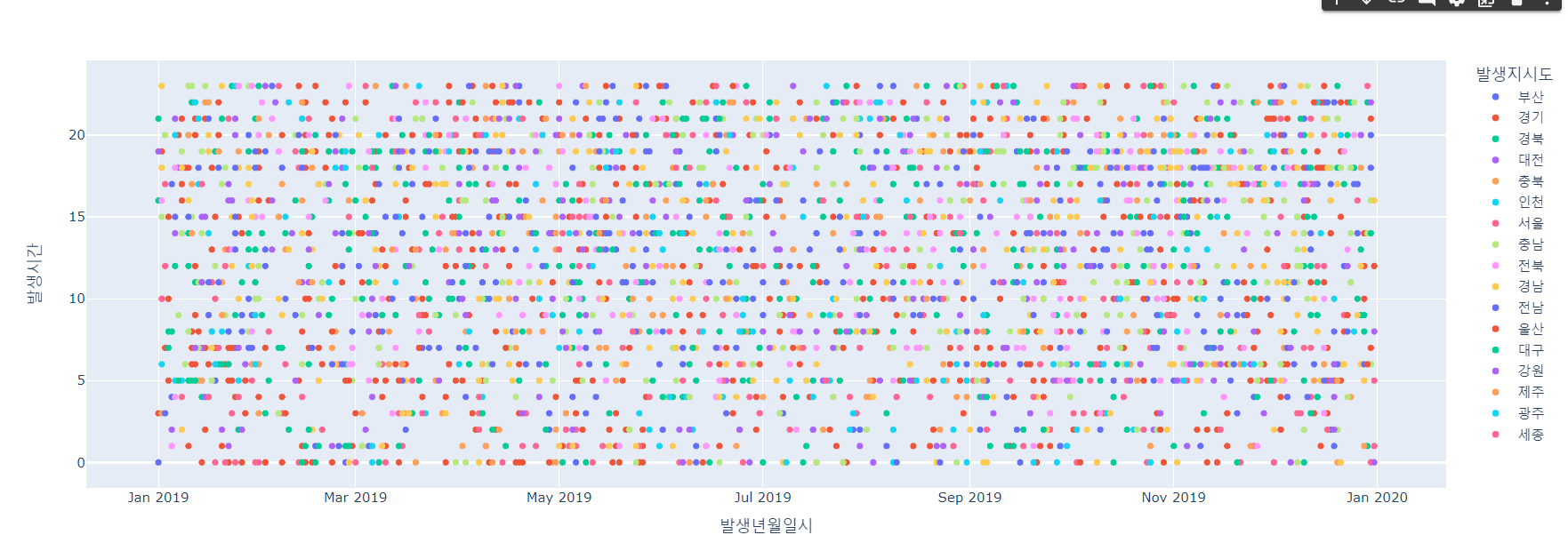
- 날짜와 시간, 지역별의 연관성을 확인하기 위한 차트 + 사망자 수에 따라서 버블을 크게 그려보자
→ 버블차트 형태로 구현이 가능하다.
fig = px.scatter(df, x='발생년월일시', y='발생시간', color='발생지시도', size = '사망자수')
fig.show()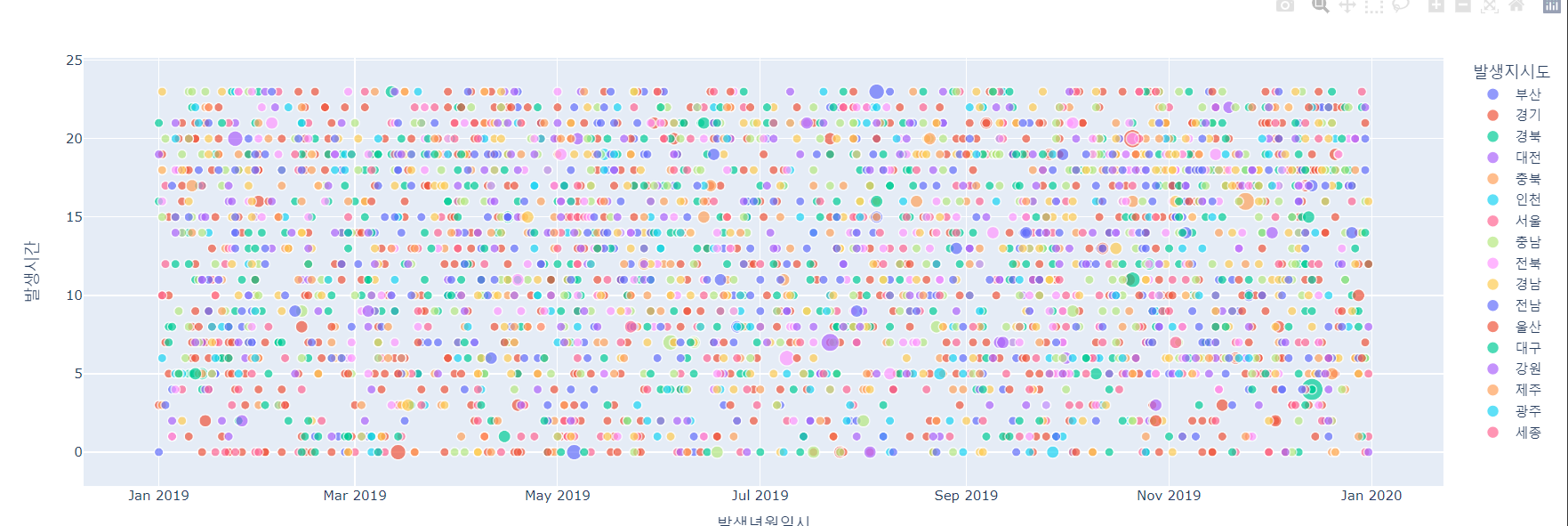
5. 시간대별 교통사고 사망자 현황
- 시간대별 교통사고 사망자 현황이니까 x축에 시간대, y축에 사망자수로 구성된 차트를 구성해보자.
fig = px.bar(df, x = '발생시간', y='사망자수')
fig.show()
- 어느 시간대가 제일 많이 발생했는지가 한눈에 확 들어오지 않는 느낌이다. 이에 x축과 y축을 바꿔서 그래프를 그려보자.
fig = px.bar(df, x = '사망자수', y='발생시간', orientation ='h')
fig.show()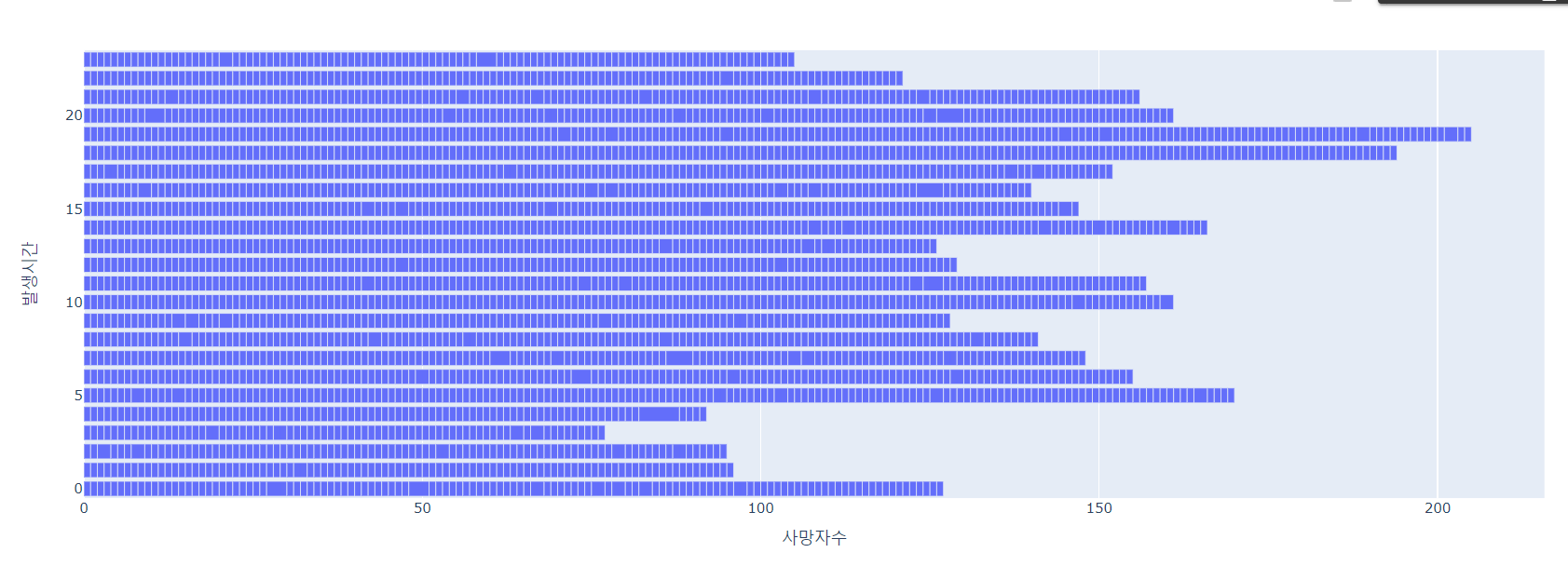
6. 시도별 교통사고 사망자 현황
- 이번에는, 도시별 교통사고 사망자 현황을 분석해보자. 이때, color= 를 이용해서 교통사고 시간이 주인지 야인지 판단하는 코드를 작성했다.
fig = px.bar(df, x = '사망자수', y='발생지시도', orientation ='h', color='주야')
fig.show()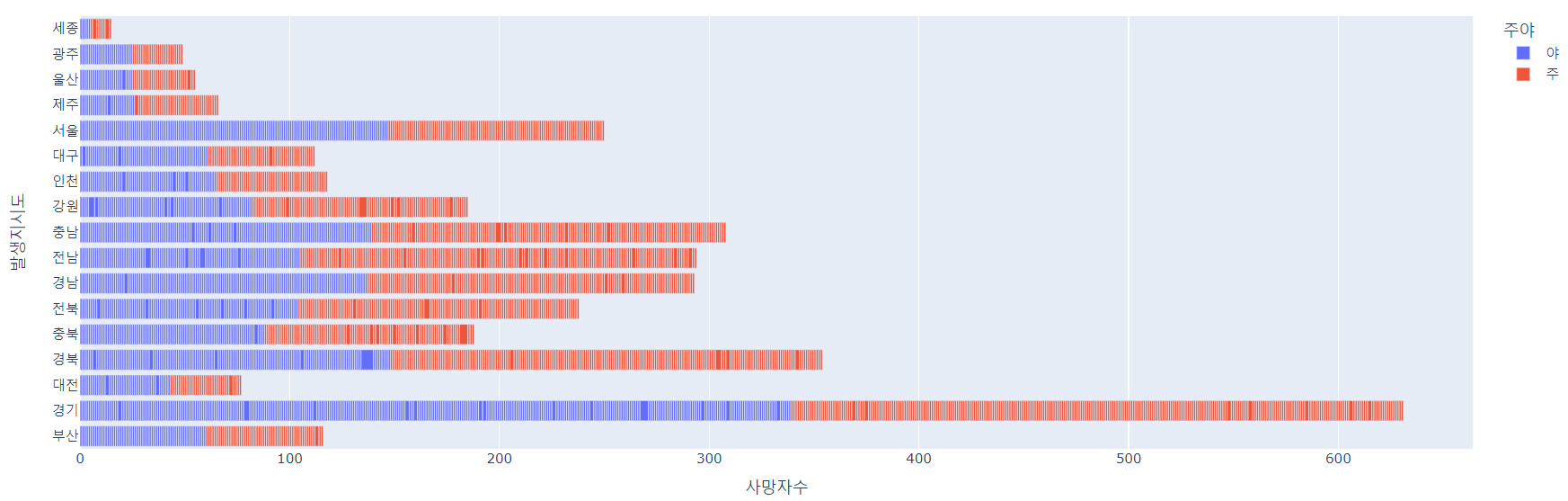
7. 요일별 교통사고 사망자 현황
- 무슨 요일이 교통사고 사망자가 가장 많은지도 분석해보자. 여기서도 마찬가지로 색을 통해 사고가 일어난 시간을 구분해보자.
fig = px.bar(df, x = '사망자수', y='요일', orientation ='h', color='주야')
fig.show()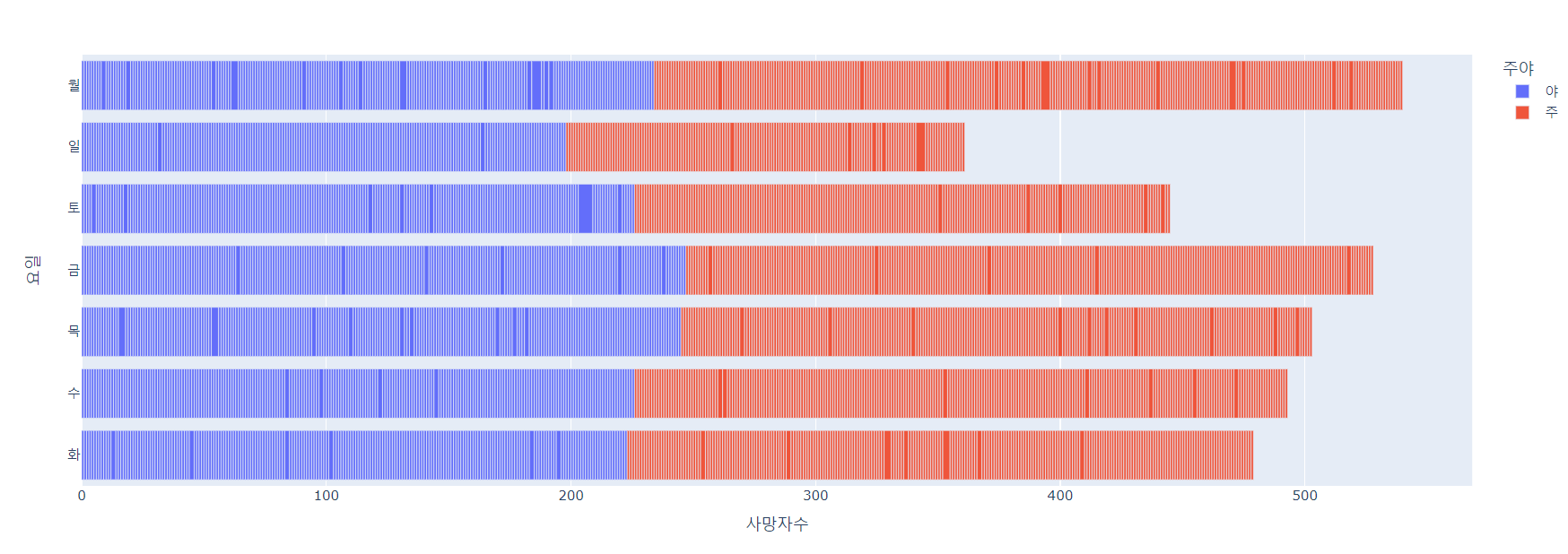
8. 사고 유형별 교통사고 사망자 현황
- 이번에는 사고 유형별로 교통사고 사망자수를 분석해보자.
fig = px.bar(df, x = '사망자수', y='사고유형', orientation ='h', color='주야')
fig.show()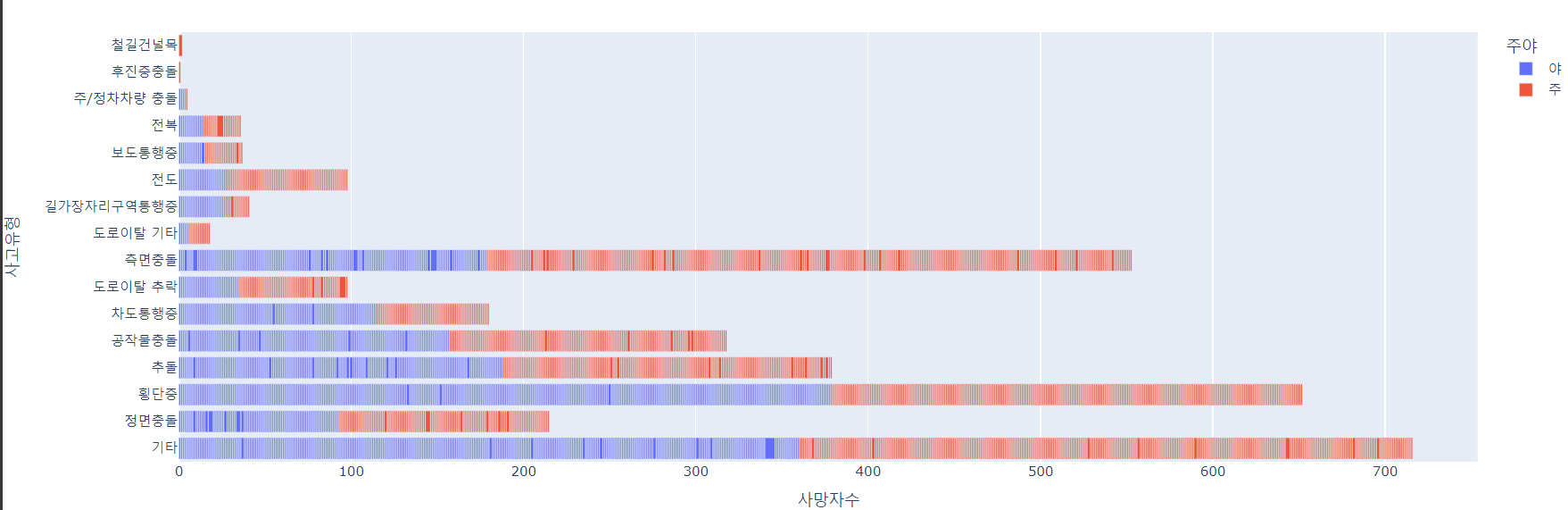
교통사고 현황 지도 시각화
[ 대전광역시 교통사고 발생 데이터 분석 ]
1. 데이터 준비하기
- 우선, csv의 데이터프레임의 데이터들 중, 대전광역시의 데이터만 따로 데이터프레임의 형태로 저장해준다.
dj_df = df[df['발생지시도'] == '대전']
dj_df.info()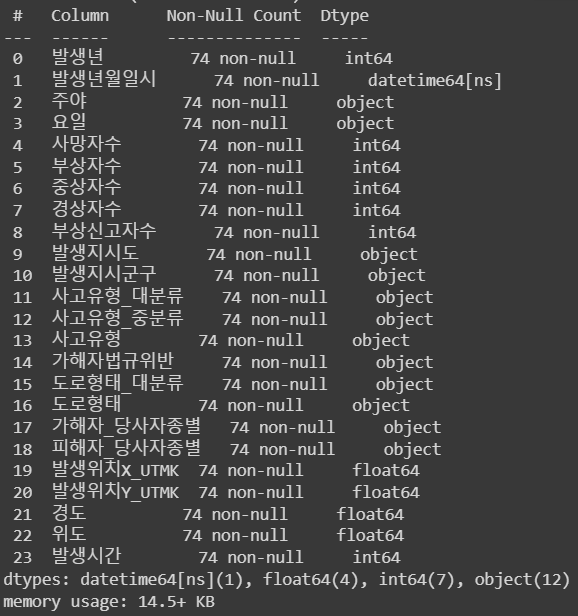
- 이 경우, 앞에서 전처리를 해서 딱히 해줄 전처리는 없으므로 바로 분석을 시작해보자.
2. 대전의 시간별 교통사고 사망자 현황
fig = px.bar(dj_df,x='사망자수', y='발생시간', orientation='h')
fig.show()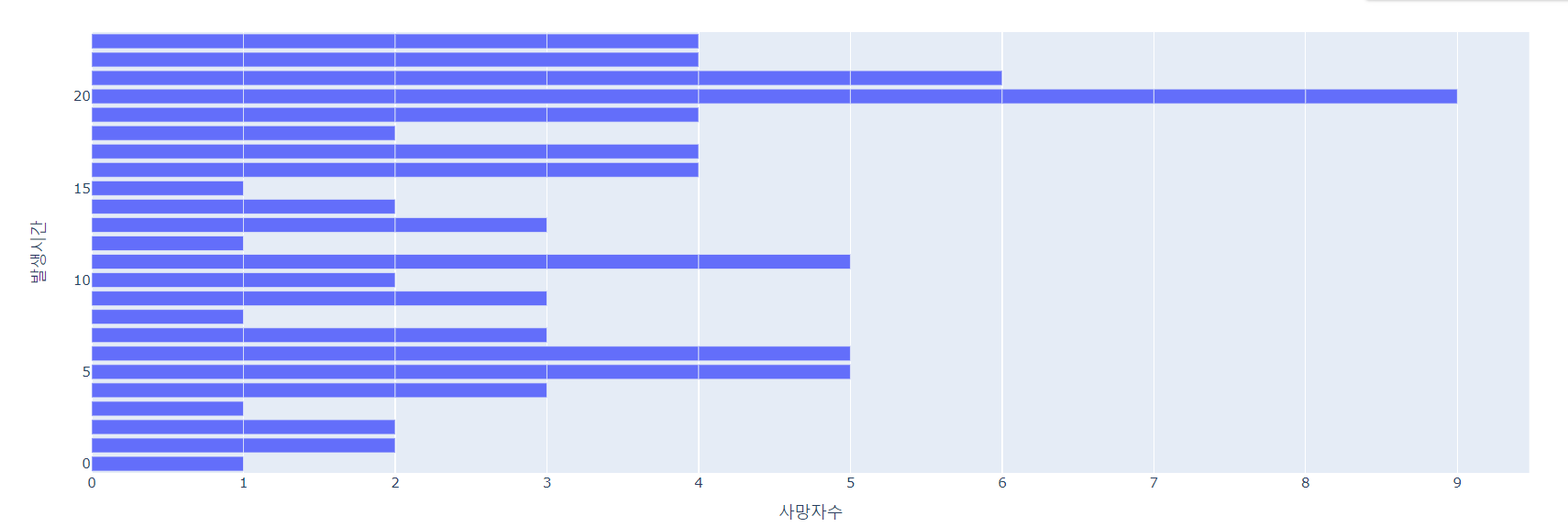
- 이 경우, 데이터 수가 적기 때문에 가로로 봐도 한눈에 파악하는 것이 가능하다.
fig = px.bar(dj_df, x='발생시간', y='사망자수')
fig.show()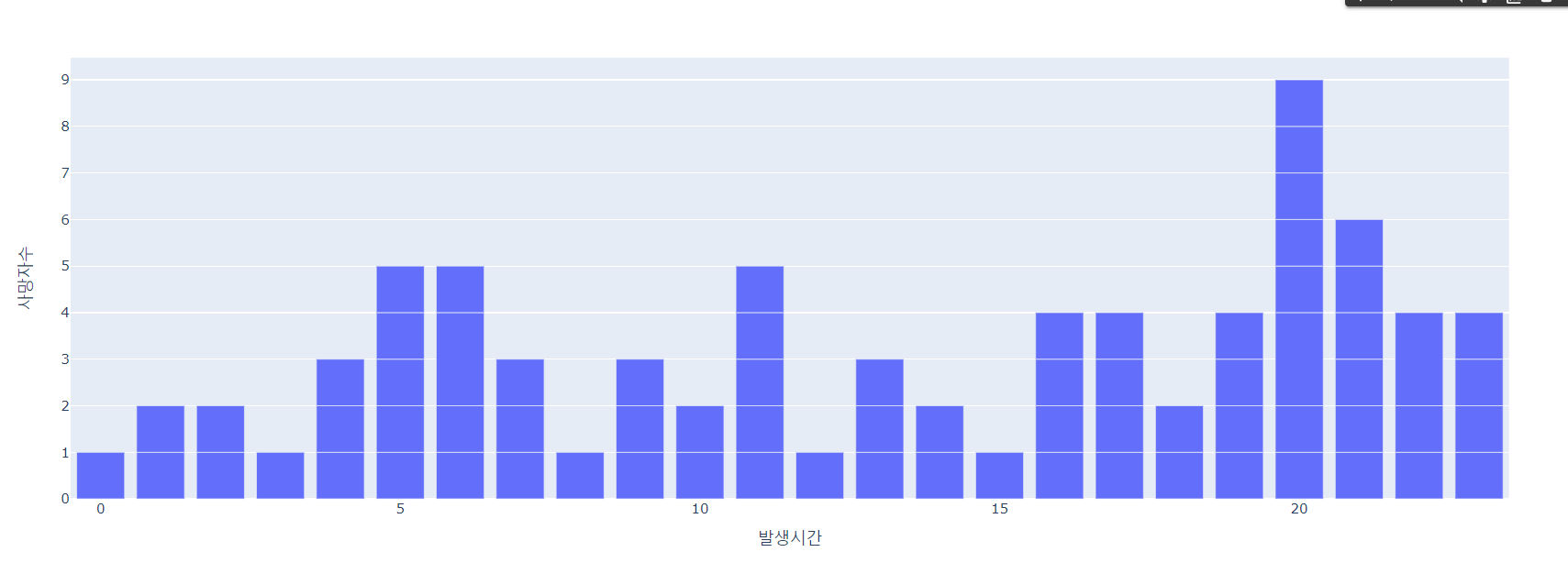
3. 대전의 요일별 교통사고 사망자 현황
fig = px.bar(dj_df,x='사망자수', y='요일', orientation='h', color='주야')
fig.show()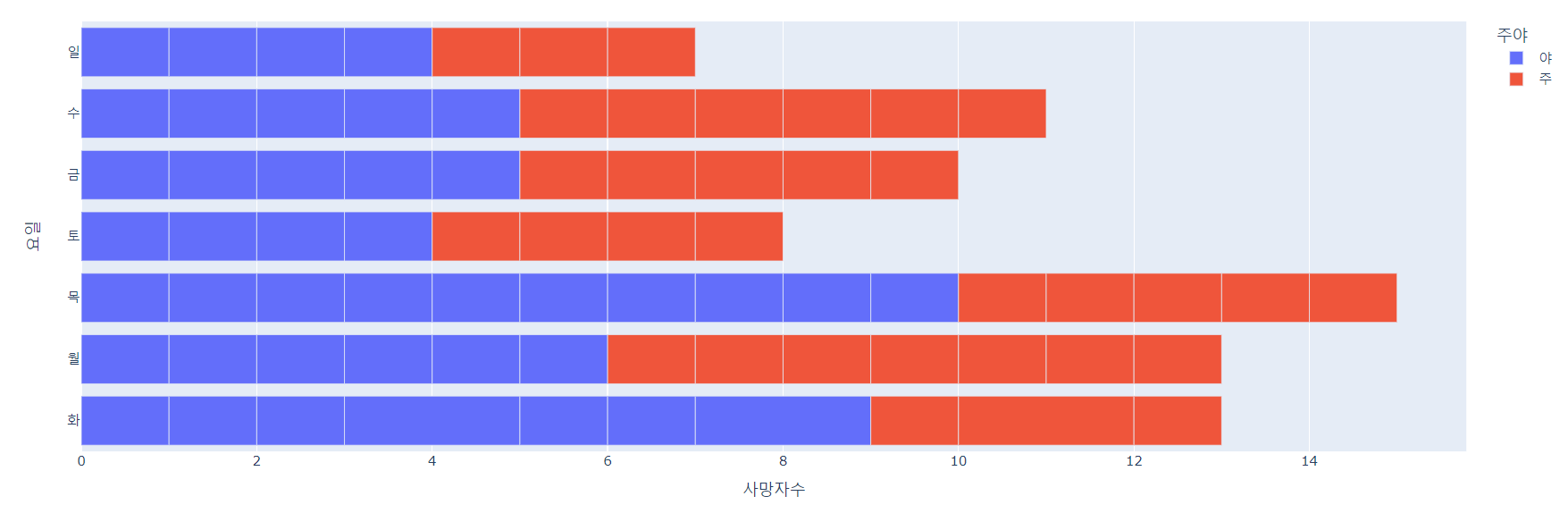
4. 대전의 지역구별 교통사고 사망자 현황
fig = px.bar(dj_df, x='발생지시군구', y='사망자수')
fig.show()
5. 대전의 사고유형별 교통사고 사망자 현황
fig = px.bar(dj_df,x='사망자수', y='사고유형', orientation='h', color='주야')
fig.show()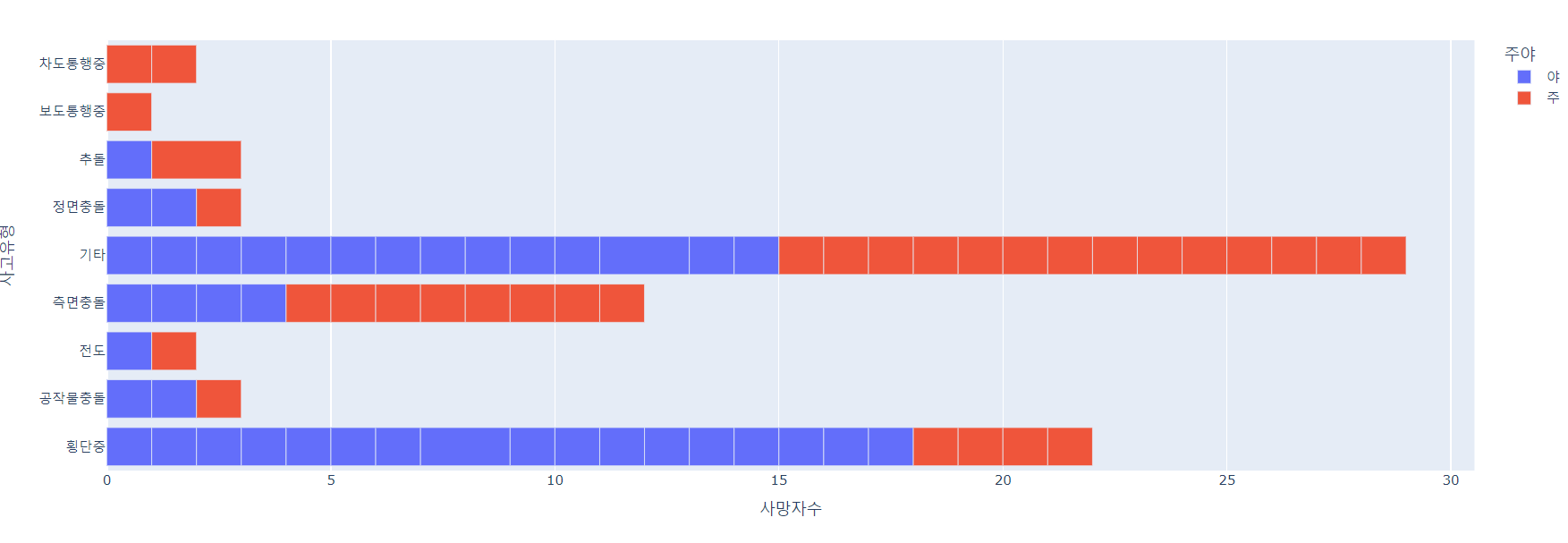
6. 지도를 활용한 교통사고 현황 분석
- 지도를 분석할 수 있는 라이브러리 임포트
import folium
- folium.Map(location=[위도,경도]) location 좌표 꼭 넣어줘야함. ==> 중심좌표
- location 중심좌표를 기준으로 지도를 그려준다.
- 지도는 보통 타일 형식으로 그려진다. → 타일의 크기에 따라 데이터가 얼마나 들어가냐의 차이가 난다. 작을수록 많이 들어가는 것
- 보통은 시청을 기준으로 잡는다. (교통 표지판도 보통 시청을 기준으로 거리를 잡음)
- 만약, 시청이 아니라 한쪽으로 시프트되어 있으면, 중심좌표를 따로 잡아서 그리는 경우도 있다.
dj_map = folium.Map(location=[36.31655,127.378953])
dj_map
7. 지도 시각화를 위한 전처리
- 사망사고 위치에 CircleMarker를 표출
- CircleMarker의 사이즈를 사망자수 + 부상자수(중상자+경상자+신고자) → circle을 클릭하면 popup 사고유형이 나타나도록 구현
- 사망자수와 부상자수는 int → float(실수형) 데이터 타입을 변환한다.(원을 그릴 때 사용되기 때문에 처리해줌. 결국, 원주율 때문이라는 소리)
dj_df = dj_df.astype({'사망자수' : 'float'})
dj_df = dj_df.astype({'부상자수' : 'float'})
dj_df.info()
- DataFrame 객체.unique() : 가지고 있는 데이터가 어떤 것들인지 파악할 수 있다.
dj_df['사고유형'].unique()
8. 사망자수 + 부상자수에 따른 CIrcleMarker 지도에 표출하기
dj_map = folium.Map(location=[36.31655,127.378953])
# dj_df 데이터가 있을 때 까지 반복적으로 CircleMarker를 지도에 add 시키는 작업(지도에 올리는 작업) -> 74번 실행
for n in dj_df.index :
cnt = dj_df['사망자수'][n] + dj_df['부상자수'][n] # circlemarker의 반지름 크기를 고정
# folium.CircleMarker([위도, 경도], 반지름사이즈, 팝업, 색, 채울색).add_to(어느 지도에 올릴건지)
folium.CircleMarker([ dj_df['위도'][n], dj_df['경도'][n]], radius = cnt*10, popup = dj_df['사고유형'][n],
color = 'blue', fill_color='blue').add_to(dj_map)
dj_map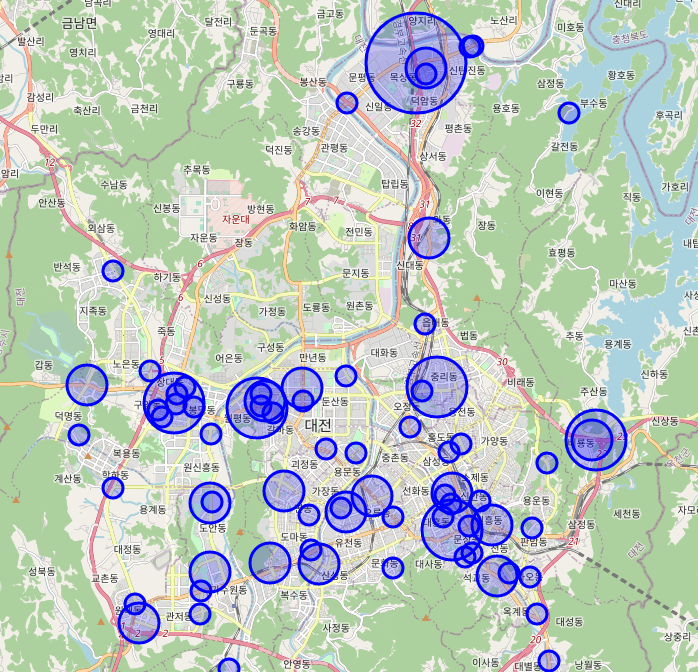
: for문은 dj_df 데이터가 있을때까지 반복적으로 CircleMarker를 지도에 add(올리는) 작업을 실행한다. CircleMarker의 반지름 크기를 고정하기 위해서 cnt라는 변수를 통해 사망자수+부상자수를 저장해준다. folium.CircleMarker([위도, 경도], 반지름사이즈, 팝업, 색, 채울색).add_to(어느지도에 올리는지)
9. 사고유형별로 횡단중이면 red, 그 외에는 blue로 그려보자.
# 사고 유형별로 횡단중이면 red, 그 외는 blue로 그려보자.
dj_map = folium.Map(location=[36.31655,127.378953])
# dj_df 데이터가 있을 때 까지 반복적으로 CircleMarker를 지도에 add 시키는 작업(지도에 올리는 작업) -> 74번 실행
for n in dj_df.index :
cnt = dj_df['사망자수'][n] + dj_df['부상자수'][n] # circlemarker의 반지름 크기를 고정
# 색을 달리 해보자
if dj_df['사고유형'][n] == '횡단중':
# folium.CircleMarker([위도, 경도], 반지름사이즈, 팝업, 색, 채울색).add_to(어느 지도에 올릴건지)
folium.CircleMarker([ dj_df['위도'][n], dj_df['경도'][n]], radius = cnt*10, popup = dj_df['사고유형'][n],
color = 'red', fill_color='red').add_to(dj_map)
elif dj_df['사고유형'][n] == '측면충돌':
# folium.CircleMarker([위도, 경도], 반지름사이즈, 팝업, 색, 채울색).add_to(어느 지도에 올릴건지)
folium.CircleMarker([ dj_df['위도'][n], dj_df['경도'][n]], radius = cnt*10, popup = dj_df['사고유형'][n],
color = 'green', fill_color='green').add_to(dj_map)
else:
folium.CircleMarker([ dj_df['위도'][n], dj_df['경도'][n]], radius = cnt*10, popup = dj_df['사고유형'][n],
color = 'blue', fill_color='blue').add_to(dj_map)
dj_map

: for 문 안에 if ~ elif ~ else 구문을 통해 CircleMarker의 색을 다르게 설정해줬다.
10. 지금까지 분석한 데이터를 html 문서로 저장하자
dj_map.save('2019대전교통사고현황.html')
'대외활동 > ABC 지역주도형 청년 취업역량강화 ESG 지원산업' 카테고리의 다른 글
| [ABC 220830 - 10일차] HTML 기초 (0) | 2022.08.31 |
|---|---|
| [ABC 220829 - 10일차] 웹기초 실습(혼자 해본 것) (0) | 2022.08.31 |
| [220824 ABC - 7일차] PYTHON 라이브러리 (0) | 2022.08.25 |
| [220824 ABC - 7일차] PYTHON 기초 (0) | 2022.08.25 |
| [220823 ABC - 6일차] PYTHON 라이브러리 (0) | 2022.08.25 |


