반응형
분류형 선형 모델 - 서포트 벡터 머신 (support vector machine, SVM)
- 데이터셋의 여러 속성을 나타내는 데이터프레임의 각 열은 열 벡터 형태로 구현 됨
- 열 벡터들이 각각 고유의 축을 갖는 벡터 공간을 만듬 → 분석 대상이 되는 개별 관측값은 모든 속성(열벡터)에 관한 값을 해당 축의 좌표로 표시하여 벡터 공간에서 위치를 나타냄
- 속성이 2개 존재하는 데이터 셋은 2차원 평면 공간 좌표, 속성 3개이면 3차원, 속성 4개이면 고차원 벡터 공간
- SVM 모형은 벡터 공간에 위치한 훈련 데이터의 좌표와 각 데이터가 어떤 분류 값을 가져야 하는지 정답을 입력 받아 학습 → 같은 분류 값을 갖는 데이터끼리 같은 공간에 위치하도록 함
- 새로운 데이터에 대해서도 어느 공간에 위치하는지 분류 가능
- SVM 모형은 학습을 통해 벡터 공간을 나누는 경계를 찾음
- 새로운 데이터는 벡터 공간에서 녹색 사각형 영역에 존재함
- SVC(Support Vector Classification) 타이타닉 생존자 예측에 따른 성능 평가
- Seaborn에서 제공하는 titanic 데이터셋 사용
- 타이타닉 데이터 전처리 (원핫인코딩 - 범주형 데이터를 모형이 인식할 수 있도록 숫자형으로 변환)
- 데이터셋 분리(훈련 셋, 테스트셋)
- →sklearn SVC(Support Vector Classification) 메소드 radial basis function (RBF) 커널 사용하여 모델 생성
SVM(Support Vector Machine) 타이타닉 생존자 예측
문제 정의 : SVM 사용하여 타이타닉 생존자(1), 사망자(0) 예측하는 이진분류모델로 정의
기본 라이브러리 임포트
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt한글 깨짐 방지
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()데이터 준비하기
df = sns.load_dataset('titanic')데이터 확인하기
df.head()
df.info()데이터 분석하기
# 예측할 값이 어떤 비율로 되어 있는지 확인
# 생존자(342), 사망자(549)의 수
df['survived'].value_counts().plot.pie(autopct='%.2f')
# 0이 사망자 1이 생존자# 생존자(342), 사망자(549)의 수
df['survived'].value_counts().plot.bar()attrs = df.columns
plt.figure(figsize=(20,20), dpi=200)
for i, feature in enumerate(attrs) :
plt.subplot(5,5,i+1)
sns.countplot(data=df, x=feature, hue='survived')
sns.despine()attrs = ['survived', 'pclass', 'sex', 'embarked', 'sibsp', 'parch']
plt.figure(figsize=(14,12), dpi=200)
for i, feature in enumerate(attrs) :
plt.subplot(3,3,i+1)
sns.countplot(data=df, x=feature, hue='survived')
sns.despine()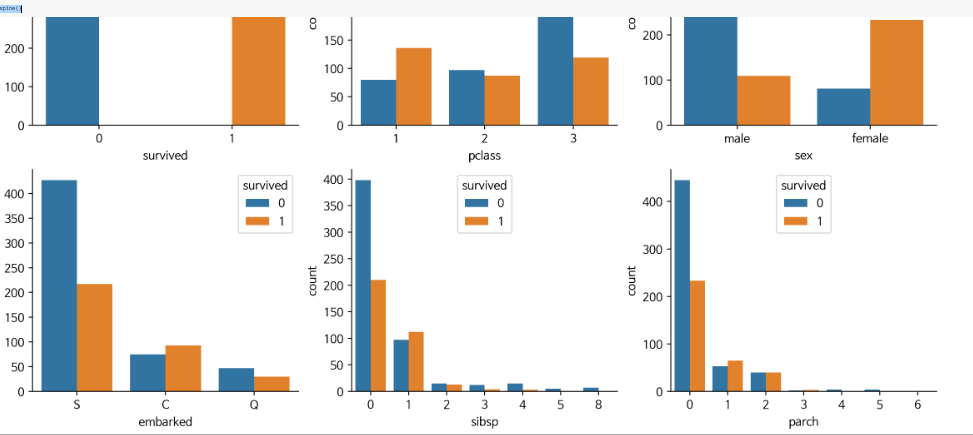
데이터 전처리
df.isna().sum()
# 1) NaN이 많은 컬럼 및 중복 컬럼 삭제 -> deck(NaN 많음), embark_town(중복)
rdf = df.drop(['deck', 'embark_town'], axis=1)
rdf.info()
# 2) age 컬럼의 데이터가 없는 row 삭제 -> age가 NaN인 177건만 삭제되도록
rdf = rdf.dropna(subset=['age'], how='any', axis=0)
rdf.info()
# 3) embarked 승선도시 NaN 데이터 2건을 어떻게 하면 채울 수 있을까? -> 승선 도시 중 가장 많이 출현한 도시로 설정
most_freq = rdf['embarked'].value_counts(dropna=True).idxmax()
# embarked 컬럼에서 수를 센 뒤 (널 값을 제외하고) 가장 큰 해당 인덱스를 가져다 줌
# 여기서 인덱스란 value_counts를 했을 때 생기는 인덱스를 의미함
# 즉, 해당 값이 출력됨
# 여기서 idxmin() 이면 가장 적게 출현한 해당 인덱스가 나옴.
most_freq
# embarked 열의 NaN 값을 승선도시 중 가장 많이 출현한 도시로 채우기
rdf['embarked'].fillna(most_freq, inplace=True)
rdf.isna().sum()
# 4) 학습에 필요한 컬럼을 선택
# 생존여부, 객실 등급, 성별, 나이, 형제/자매수, 부모/자녀수, 탑승도시
ndf = rdf[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'embarked']]
ndf.head()
# 5) 문자로 되어 있는 값을 변환 -> 인코딩 -> 원핫 인코딩(범주형 데이터를 머신러닝 모델이 인식할 수 있도록 숫자형으로 변환) 사용
# ex) male [1,0], female [0,1]
# ex) S[1,0,0], C[0,1,0], Q[0,0,1]
# 5-1) onehot 인코딩 만들기
onehot_sex = pd.get_dummies(ndf['sex'])
onehot_embarked = pd.get_dummies(ndf['embarked'])
# 5-2) ndf 데이터 프레임에 연결
ndf = pd.concat([ndf, onehot_sex], axis=1)
ndf = pd.concat([ndf, onehot_embarked], axis=1)
ndf.head()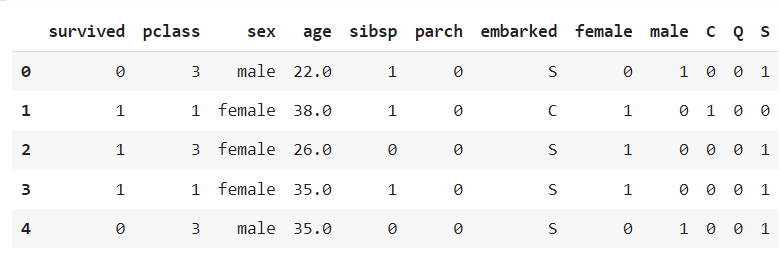
# 6) 기존 컬럼 삭제
ndf.drop(['sex', 'embarked'], axis=1, inplace=True)ndf.head()
데이터 분리하기
X = ndf[['pclass', 'age', 'sibsp', 'parch', 'female', 'male', 'C', 'Q', 'S']]
y = ndf['survived']X
y
# X (feature, 독립변수) 값을 정규화 -> 0 ~ 1 사이로 값을 줄여주는 작업 -> 스케일링(범위 조정)
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
X
# train, test set으로 분리(7:3)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=7)
print('train shape', X_train.shape)
print('test shape', X_test.shape)
SVM 분류 모델 설정
from sklearn import svm
# 모델 객체 생성 kernel='rbf'
# 벡터 공간을 맵핑하는 함수 -> 선형(linear), 다항식(ploy), 가우시안 RBF(rbf), 시그모이드(sigmoid)
svm_model = svm.SVC(kernel='rbf')svm_model.fit(X_train, y_train)
모델 성능 평가
print('훈련 세트 점수 : {:.8f}'.format(svm_model.score(X_train, y_train)))
print('테스트 세트 점수 : {:.8f}'.format(svm_model.score(X_test, y_test)))
from sklearn import metrics
y_pred = svm_model.predict(X_test)
print('accuracy : ', metrics.accuracy_score(y_test, y_pred))
print('precision : ', metrics.precision_score(y_test, y_pred))
print('recall : ', metrics.recall_score(y_test, y_pred))
print('f1 : ', metrics.f1_score(y_test, y_pred))
LIST
'대외활동 > ABC 지역주도형 청년 취업역량강화 ESG 지원산업' 카테고리의 다른 글
| [ABC 220923] 지도 학습 알고리즘 - 결정 트리 (1) | 2022.10.18 |
|---|---|
| [ABC 220923] 지도 학습 알고리즘 - 선형 모델 정리 (1) | 2022.10.18 |
| [ABC 220923] 지도 학습 알고리즘 - 다중 클래스 분류형 선형 모델 (0) | 2022.10.18 |
| [ABC 220923] 지도 학습 알고리즘 - 분류형 선형 모델 (1) | 2022.10.18 |
| [ABC 220921] 지도 학습 알고리즘 -Ridge 회귀 / Lasso 회귀 (1) | 2022.10.18 |

