반응형
군집 (clustering)
- 군집(clustering)은 데이터셋을 클러스터(cluster)라는 그룹으로 나누는 작업
- 군집 분석은 데이터셋 관측값이 갖고 있는 여러 속성을 분석하여 서로 비슷한 특징을 갖는 관측값끼리 같은 클러스터(집단)으로 묶는 알고리즘
- 다른 클러스터 간에는 서로 완전하게 구분되는 특징을 갖기 때문에 어느 클러스터에도 속하지 못하는 관측값이 존재할 수 있음
- 관측값을 몇 개의 집단으로 나눈다는 점에서 분류 알고리즘과 비슷 BUT 정답이 없는 상태에서 데이터 자체의 유사성만을 기준으로 판단하는 점이 다름
- 신용카드 부정 사용 탐지, 구매 패턴 분석 등 소비자 행동 특성 그룹화
- 어떤 소비자와 유사한 특성을 갖는 집단 구분 → 갖은 집단 내의 다른 소비자를 통해 새로운 소비자의 구매 패턴이나 행동 예측에 활용
- k-Means 알고리즘, DBSCAN 알고리즘
- 군집 분석은 데이터셋 관측값이 갖고 있는 여러 속성을 분석하여 서로 비슷한 특징을 갖는 관측값끼리 같은 클러스터(집단)으로 묶는 알고리즘
군집(clustering) 알고리즘
- 군집(clustering)은 데이터셋을 클러스터(cluster)라는 그룹으로 나누는 작업
- k-평균 군집
- 가장 간단하고 널리 사용하는 군집 알고리즘
- 데이터의 어떤 영역을 대표하는 클러스터 중심 찾기
- 병합 군집
- 군집 알고리즘의 모음
- 종료 조건 만족까지 비슷한 클러스터 합치기
- DBSCAN
- 데이터가 위치하고 있는 공간 밀집도 기준으로 클러스터 구분
k-평균 군집 (k-Means)
- 데이터 간의 유사성을 측정하는 기준으로 각 클러스터의 중심까지의 거리를 이용
- 벡터 공간에 위치한 어떤 데이터에 대해서 k개의 클러스터가 주어졌을 때 클러스터의 중심까지 거리가 가장 가까운 클러스터로 해당 데이터를 할당
- 다른 클러스터 간에는 서로 완전하게 구분하기 위해 일정한 거리 이상 떨어져야함
- 몇 개의 클러스터로 데이터를 구분할 것인지 생성하는 k 값에 따라 모형의 성능이 달라짐
- 일반적으로 k가 클수록 모형의 정확도가 개선
- k 값이 너무 커지면 선택지가 너무 많아지므로 분석의 효과가 사라짐
k-평균 군집(k-Means) 예제
- Kmeans 도매업 고객 군집 분석
- UCL ML Repository의 도매업 고객(wholesale customers) 데이터 셋 사용
- https://archive.ics.uci.edu/ml/datasets/wholesale+customers
- 데이터 전처리 (StandardScaler() 데이터 정규화 ; 특정 범위 값으로 데이터 범위 축소)
- 데이터 셋 분리(훈련셋, 테스트셋) → Kmeans 메소드 n_clusters 5를 적용하여 모델 생성 → 클러스터 데이터 시각화
K-Means 도매업 고객 군집 분석
문제 정의 : 도매업(clients of a wholesale distributor) 데이터 셋을 활용한 군집 분석
기본 라이브러리 임포트
import pandas as pd
import matplotlib.pyplot as plt데이터 준비하기
# Wholesale customers 데이터셋 가져오기 (출처 : UCI ML Repository)
# uci_path = 'https://archive.ics.uci.edu/ml/machine-learning-databases/
# clients of a wholesale distributor 각 품목에 대한 연간 지출
uci_path = 'https://archive.ics.uci.edu/ml/machine-learning-databases/\
00292/Wholesale%20customers%20data.csv'
df = pd.read_csv(uci_path, header=0)
df.head()
데이터 확인하기
df.info()df.Channel.unique()
# Horeca (Hotel/Restaurant/Cafe) or Retail channel (Nominal)df.Region.unique()
# Lisnon, Oporto ot Other (Nominal)데이터 전처리
X = df.iloc[: , :]
X.shapeX.head()# 데이터 정규화 -> 스케일링
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)Xtype(X)K-Means 군집 모델 설정
from sklearn import cluster
kmeans = cluster.KMeans(n_clusters=5)모델 학습하기
kmeans.fit(X)
cluster_label = kmeans.labels_ # 0~4까지 군집 생성
cluster_label
클러스터 데이터 시각화
df['Cluster'] = cluster_label
df.head()
df['Cluster'].unique()
# Channel(채널)과 Region(지역)의 연관 관계
# 2 Cluster Channel 2, Region 1, 2, 3
# 1 Cluster Channel 1, Region 3
# 0 Cluster Channel 1, Region 1, 2
df.plot(kind='scatter', x='Channel', y='Region', c='Cluster', cmap='Set1', figsize=(10,10))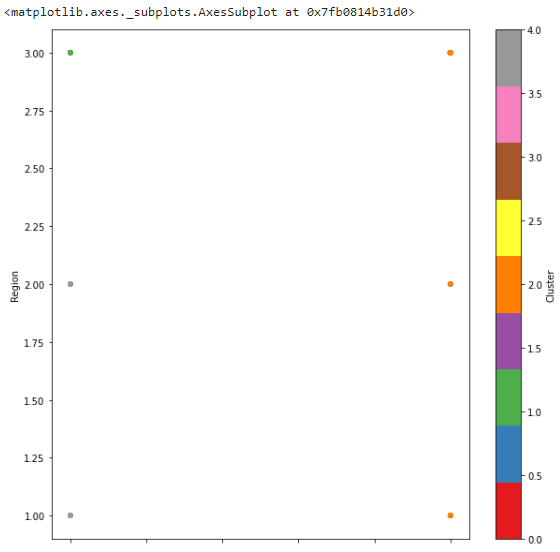
# 품목들간의 연관 관계 Milk, Fresh
df.plot(kind='scatter', x='Milk', y='Fresh', c='Cluster', cmap='Set1', figsize=(10,10))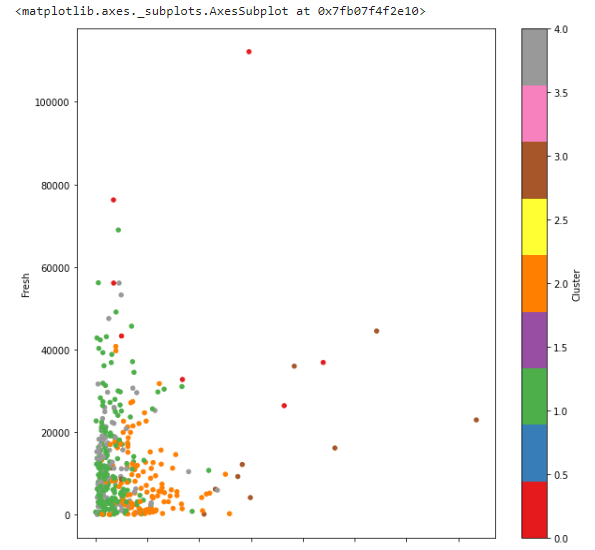
# 품목들간의 연관 관계 Frozen, Detergents_Paper
df.plot(kind='scatter', x='Frozen', y='Detergents_Paper', c='Cluster', cmap='Set1', figsize=(10,10))
# 주황색 2, 갈색 3번 클러스터 만 더 자세하게 보고 싶다.
mask = (df['Cluster'] == 2) | (df['Cluster'] == 0)
ndf = df[mask]
ndf.Cluster.unique()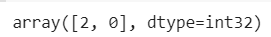
ndf.plot(kind='scatter', x='Frozen', y='Detergents_Paper', c='Cluster', cmap='Set1', figsize=(10,10))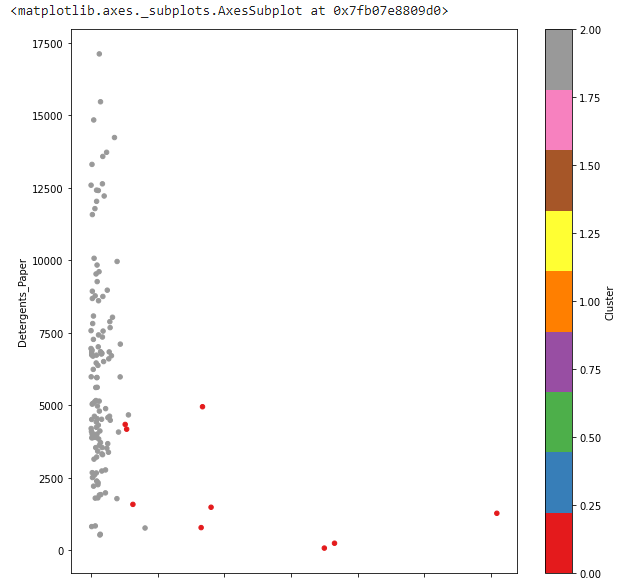
# 주황색 2, 갈색 1번 클러스터를 제외한 0, 3, 4번만 더 자세하게 보고 싶다.
mask = (df['Cluster'] == 2) | (df['Cluster'] == 0)
ndf = df[~mask]
ndf.plot(kind='scatter', x='Frozen', y='Detergents_Paper', c='Cluster', cmap='Set1', figsize=(10,10))
# 데이터프레임을 사용해 df['Cluster'] 따라서 색으로 구분된 산점도 행렬
pd.plotting.scatter_matrix(df, c=df['Cluster'], figsize=(20,20), marker='o', hist_kwds={'bins' : 20}, s=60, alpha=0.8)
plt.tight_layout()
import numpy as np
plt.imshow([np.unique(df['Cluster'])])
plt.show()
len(df[df['Cluster'] == 1])
len(df[df['Cluster'] == 3])
len(df[df['Cluster'] == 0])
LIST
'대외활동 > ABC 지역주도형 청년 취업역량강화 ESG 지원산업' 카테고리의 다른 글
| [ABC 220927] 비지도 학습 요약 및 정리 (0) | 2022.10.20 |
|---|---|
| [ABC 220927] 비지도 학습 - DBSCAN (0) | 2022.10.20 |
| [ABC 220927] 비지도 학습 (0) | 2022.10.20 |
| [ABC 220926] 특강 - "개발자란" (0) | 2022.10.20 |
| [ABC 220926] 특강 "야나두 할 수 있는 재무설계" (0) | 2022.10.20 |

