2019년도와 2021년도의 교통사고 데이터를 비교해보자.
라이브러리 임포트
import pandas as pd
import plotly.express as px데이터 준비하기
- 2019년
df1 = pd.read_csv('/content/도로교통공단_교통사고 정보.csv', encoding='euc-kr')
df1.head()
- 2021년
df2 = pd.read_csv('/content/도로교통공단_사망 교통사고 정보_20211231.csv', encoding='euc-kr')
df2.head()교통사고 데이터 전처리
- 2019년 버전
df1 = df1.astype({'발생년월일시' : 'string'})
df1.info()df1['발생시간'] = df1['발생년월일시'].str[8:]
df1 = df1.astype({'발생시간' : 'int64'})
df1.info()df1['발생년월일시'] = pd.to_datetime(df1['발생년월일시'].str[:8], format='%Y-%m-%d', errors = 'raise')
df1.info()- 2021년 버전
df2 = df2.astype({'발생년월일시':'string'})
df2.info()df2['발생시간'] = df2['발생년월일시'].str[11:13]
df2 = df2.astype({'발생시간':'int64'})
df2.info()
df2['발생년월일시'] = pd.DataFrame(df2['발생년월일시'].str[:11])데이터 분석을 해보자
# 2019 년 scatter 차트
fig = px.scatter(df1, x = '발생년월일시', y='발생시간', color = '발생지시도', size = '사망자수')
fig.show()
# 2021 년 scatter 차트
fig = px.scatter(df2, x = '발생년월일시', y='발생시간', color = '발생지시도', size = '사망자수')
fig.show()
Q1. 시간대별 교통사고 현황 => 제일 사고가 많았던 시간은 몇시?
# 2019년 발생시간별 사망자수 데이터
fig = px.bar(df1, x = '사망자수', y='발생시간', orientation='h')
fig.show()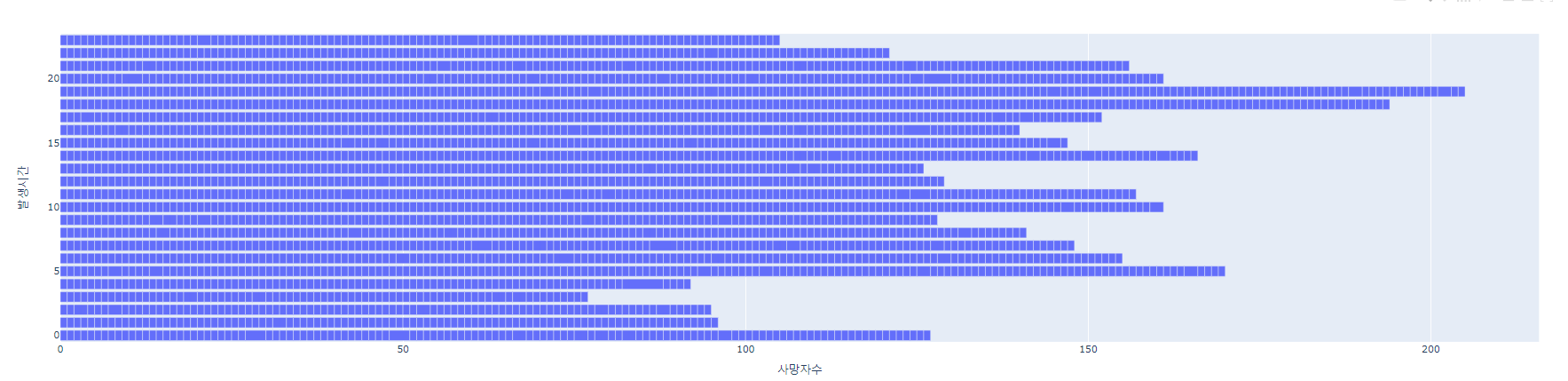
# 2019년 데이터를 이용해서 시간대별 교통사고 수를 세보자.
cnt = [0]*24
for i in df1.index:
for k in range(24) :
if df1['발생시간'][i] == k:
cnt[k] += 1
print(cnt)
print("2019년에 가장 사고가 많았던 시간은",cnt.index(max(cnt)),"시 입니다" )
# 2021년 발생시간별 사망자수 데이터
fig = px.bar(df2, x = '사망자수', y='발생시간', orientation='h')
fig.show()

# 2021년 데이터를 이용해서 시간대별 교통사고 수를 세보자.
cnt2 = [0]*24
for i in df2.index:
for k in range(24) :
if df2['발생시간'][i] == k:
cnt2[k] += 1
print(cnt2)
print("2021년에 가장 사고가 많았던 시간은",cnt2.index(max(cnt2)),"시 입니다" )
: 왜 사고가 가장 많았던 시간이 19시 -> 18시로 바뀌었을까?
Q2. 지역별 교통사고 현황 => 사고가 제일 많았던 도시는?
# 2019년 사망자수 데이터
fig = px.bar(df1, x = '사망자수', y='발생지시도', orientation = 'h', color='주야')
fig.show()
# 2019년 데이터를 이용해서 지역별 교통사고 수를 세보자.
count1 = [0]*17
city=['부산', '경기', '대전', '경북', '충북', '전북', '경남', '전남', '충남', '강원', '인천', '대구', '서울', '제주', '울산', '광주', '세종']
for i in df1.index:
if df1['발생지시도'][i] == '부산':
count1[0] += 1
elif df1['발생지시도'][i] == '경기':
count1[1] += 1
elif df1['발생지시도'][i] == '대전':
count1[2] += 1
elif df1['발생지시도'][i] == '경북':
count1[3] += 1
elif df1['발생지시도'][i] == '충북':
count1[4] += 1
elif df1['발생지시도'][i] == '전북':
count1[5] += 1
elif df1['발생지시도'][i] == '경남':
count1[6] += 1
elif df1['발생지시도'][i] == '전남':
count1[7] += 1
elif df1['발생지시도'][i] == '충남':
count1[8] += 1
elif df1['발생지시도'][i] == '강원':
count1[9] += 1
elif df1['발생지시도'][i] == '인천':
count1[10] += 1
elif df1['발생지시도'][i] == '대구':
count1[11] += 1
elif df1['발생지시도'][i] == '서울':
count1[12] += 1
elif df1['발생지시도'][i] == '제주':
count1[13] += 1
elif df1['발생지시도'][i] == '울산':
count1[14] += 1
elif df1['발생지시도'][i] == '광주':
count1[15] += 1
else :
count1[16] += 1
count_1 = pd.Series(count1, index=['부산', '경기', '대전', '경북', '충북', '전북', '경남', '전남', '충남', '강원', '인천', '대구', '서울', '제주', '울산', '광주', '세종'])
print(count1)
print("2019년에 가장 사고가 많았던 도시는",count_1.idxmax(),"입니다" )
# 2021년 사망자수 데이터
fig = px.bar(df2, x = '사망자수', y='발생지시도', orientation = 'h', color='주야')
fig.show()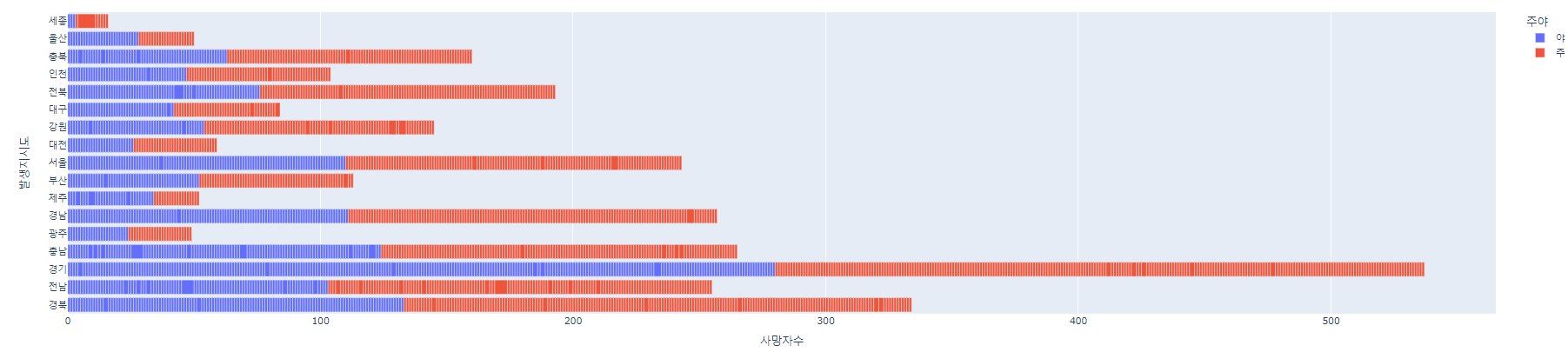
# 2021년 데이터를 이용해서 지역별 교통사고 수를 세보자.
count2 = [0]*17
city=['부산', '경기', '대전', '경북', '충북', '전북', '경남', '전남', '충남', '강원', '인천', '대구', '서울', '제주', '울산', '광주', '세종']
for i in df2.index:
if df2['발생지시도'][i] == '부산':
count2[0] += 1
elif df2['발생지시도'][i] == '경기':
count2[1] += 1
elif df2['발생지시도'][i] == '대전':
count2[2] += 1
elif df2['발생지시도'][i] == '경북':
count2[3] += 1
elif df2['발생지시도'][i] == '충북':
count2[4] += 1
elif df2['발생지시도'][i] == '전북':
count2[5] += 1
elif df2['발생지시도'][i] == '경남':
count2[6] += 1
elif df2['발생지시도'][i] == '전남':
count2[7] += 1
elif df2['발생지시도'][i] == '충남':
count2[8] += 1
elif df2['발생지시도'][i] == '강원':
count2[9] += 1
elif df2['발생지시도'][i] == '인천':
count2[10] += 1
elif df2['발생지시도'][i] == '대구':
count2[11] += 1
elif df2['발생지시도'][i] == '서울':
count2[12] += 1
elif df2['발생지시도'][i] == '제주':
count2[13] += 1
elif df2['발생지시도'][i] == '울산':
count2[14] += 1
elif df2['발생지시도'][i] == '광주':
count2[15] += 1
else :
count2[16] += 1
count_2 = pd.Series(count2, index=['부산', '경기', '대전', '경북', '충북', '전북', '경남', '전남', '충남', '강원', '인천', '대구', '서울', '제주', '울산', '광주', '세종'])
print(count2)
print("2021년에 가장 사고가 많았던 도시는",count_2.idxmax(),"입니다" )
# 2019년 경기 지역 교통사고 수와 2021년 경기 지역 교통사고 수 비교
print(count1)
print(count2)
print()
print("2019년 경기 지역의 교통사고 횟수는",count_1['경기'],"회 입니다")
print("2021년 경기 지역의 교통사고 횟수는",count_2['경기'],"회 입니다")
: 2019년과 2021년 모두 경기 지역에서 가장 교통사고 횟수가 많았다. 2019년에 비해서 2021년이 더욱 교통사고 횟수가 줄어들었다. 왜일까?
Q3. 요일별 교통사고 현황 보기
# 2019년
fig = px.bar(df1, x = '사망자수', y='요일', orientation='h', color='주야')
fig.show()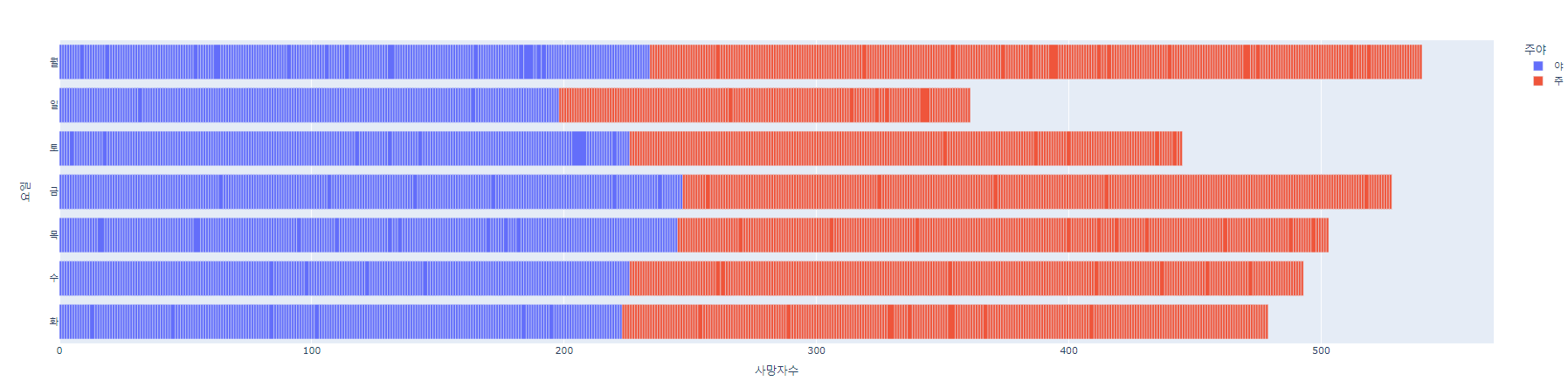
# 2019년 데이터를 이용해서 요일별 교통사고 수를 세보자.
c_day = [0]*7
day = ['월', '화', '수', '목', '금', '토', '일']
for i in df1.index:
if df1['요일'][i] == '월' :
c_day[0] += 1
elif df1['요일'][i] == '화' :
c_day[1] += 1
elif df1['요일'][i] == '수' :
c_day[2] += 1
elif df1['요일'][i] == '목' :
c_day[3] += 1
elif df1['요일'][i] == '금' :
c_day[4] += 1
elif df1['요일'][i] == '토' :
c_day[5] += 1
else :
c_day[6] += 1
day_count = pd.Series(c_day, index=day)
print(day_count)
print("2019년에 가장 사고가 많았던 요일은",day_count.idxmax(),"요일입니다" )
# 2021년
fig = px.bar(df2, x = '사망자수', y='요일', orientation='h', color='주야')
fig.show()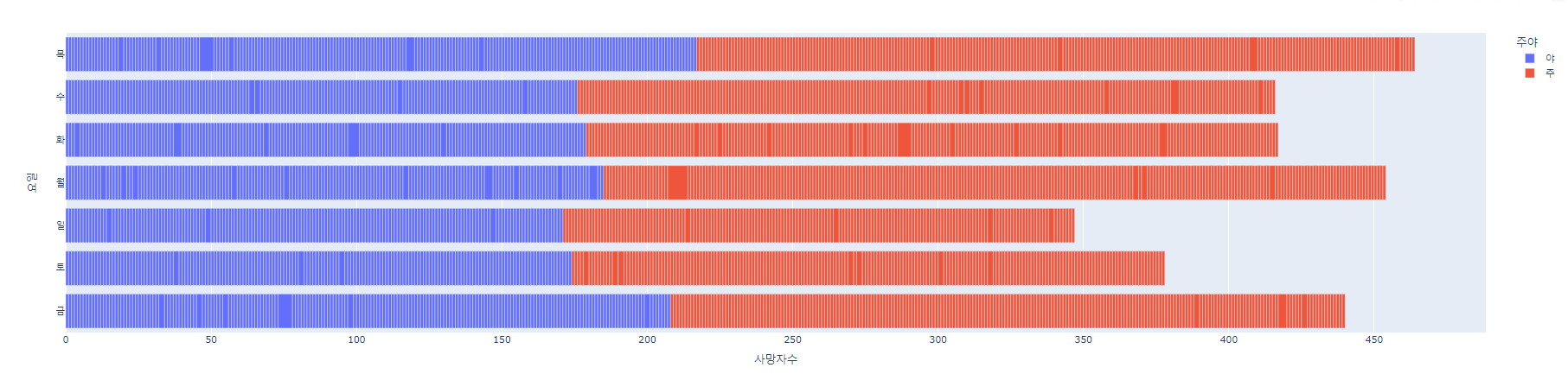
# 2021년 데이터를 이용해서 요일별 교통사고 수를 세보자.
c_day2 = [0]*7
day = ['월', '화', '수', '목', '금', '토', '일']
for i in df2.index:
if df2['요일'][i] == '월' :
c_day2[0] += 1
elif df2['요일'][i] == '화' :
c_day2[1] += 1
elif df2['요일'][i] == '수' :
c_day2[2] += 1
elif df2['요일'][i] == '목' :
c_day2[3] += 1
elif df2['요일'][i] == '금' :
c_day2[4] += 1
elif df2['요일'][i] == '토' :
c_day2[5] += 1
else :
c_day2[6] += 1
day_count2 = pd.Series(c_day2, index=day)
print(day_count2)
print("2021년에 가장 사고가 많았던 요일은",day_count2.idxmax(),"요일입니다" )
: 2019년은 금요일에, 2021년에는 목요일에 교통사고가 가장 많았다. 왜일까?
서울 데이터 분석
# 2019
su_df1 = df1[df1['발생지시도'] == '서울']
su_df1.info()
# 2021
su_df2 = df2[df2['발생지시도'] == '서울']
su_df2.info()
서울 발생시간별 교통사고 현황
# 2019
fig = px.bar(su_df1,x='사망자수', y='발생시간', orientation='h')
fig.show()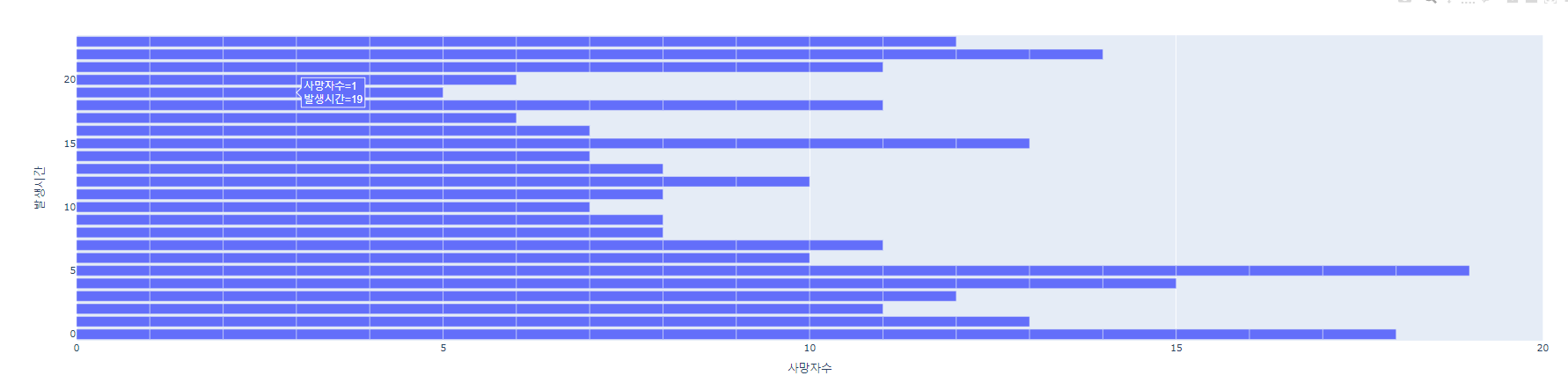
# 2021
fig = px.bar(su_df2,x='사망자수', y='발생시간', orientation='h')
fig.show()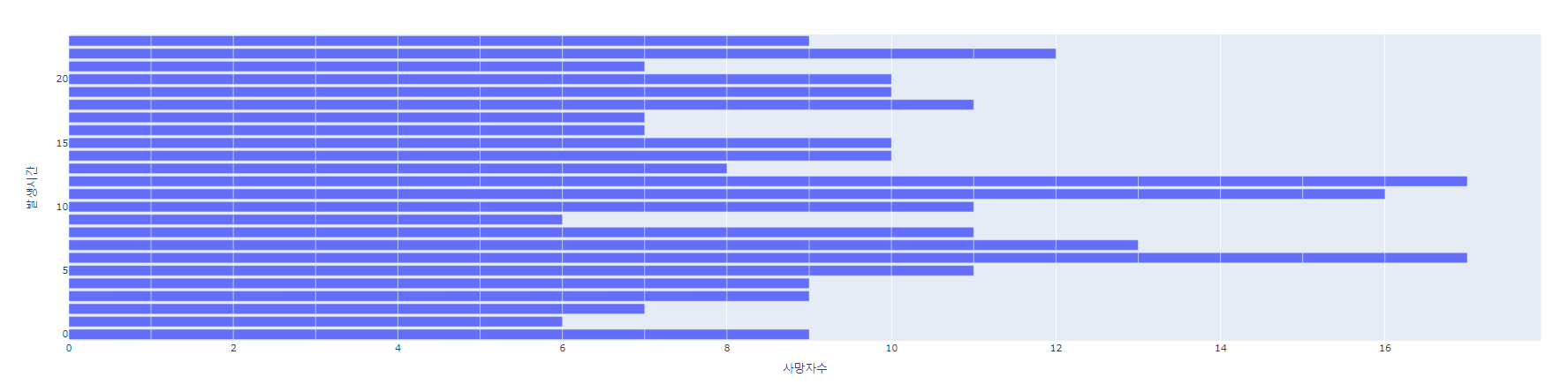
서울 요일별 교통사고 현황
# 2019
fig = px.bar(su_df1, x = '사망자수', y = '요일', orientation='h', color='주야')
fig.show()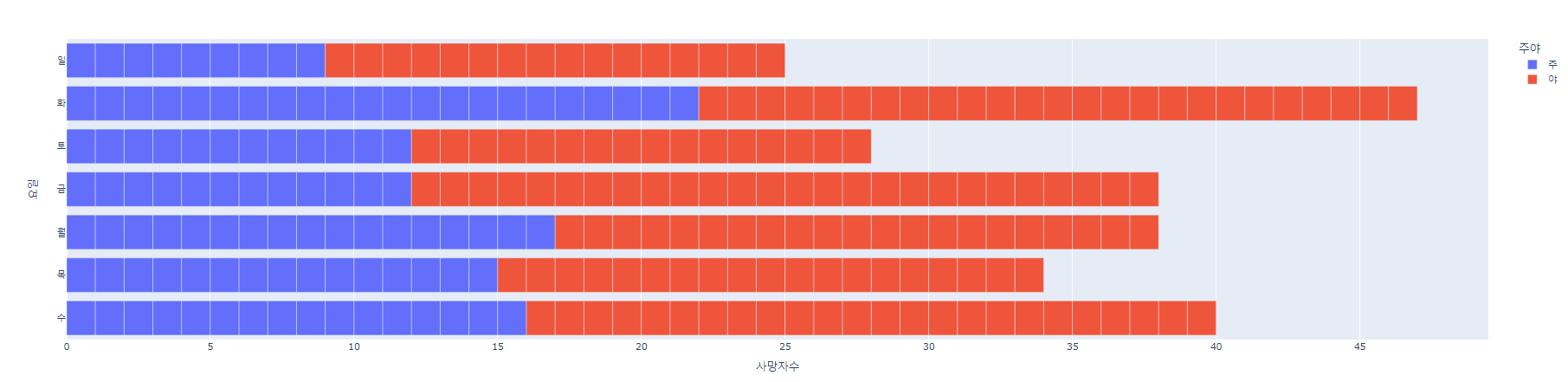
# 2021
fig = px.bar(su_df2, x = '사망자수', y = '요일', orientation='h', color='주야')
fig.show()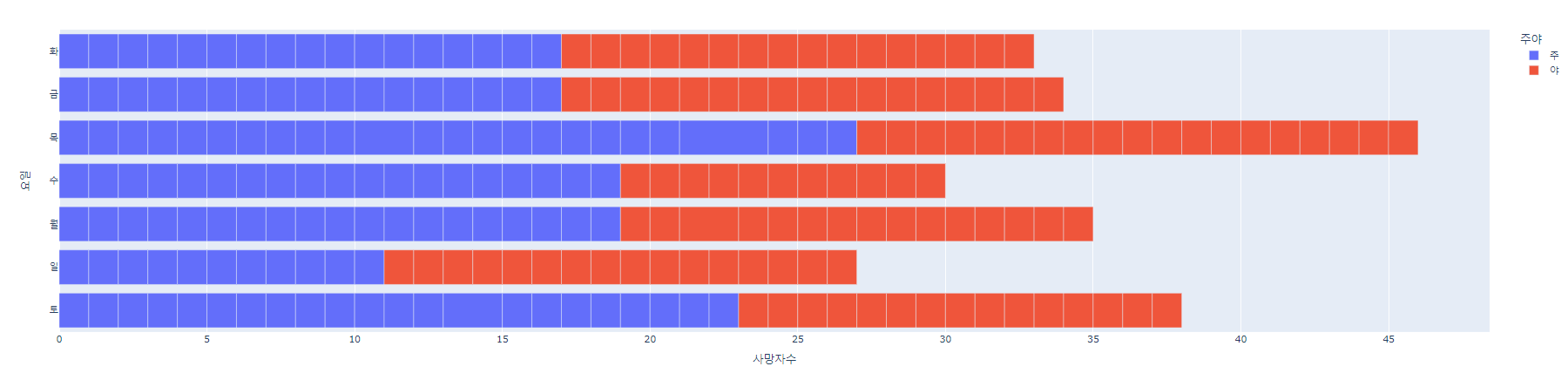
서울 지역구별 교통사고 사망자 현황
# 2019
fig = px.bar(su_df1, x ='발생지시군구', y='사망자수')
fig.show()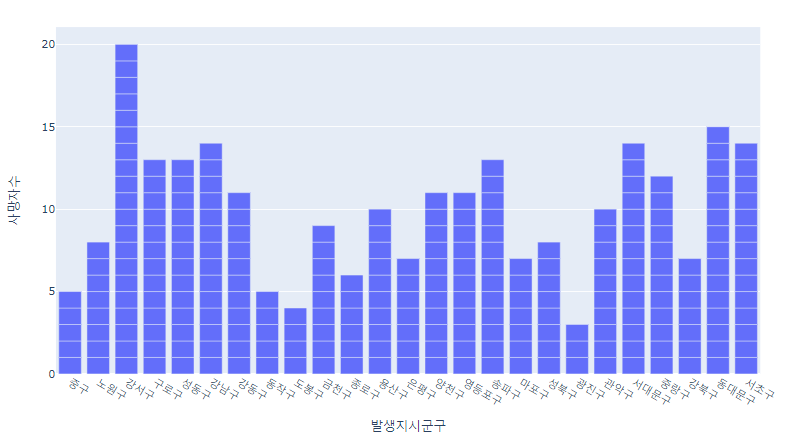
# 2021
fig = px.bar(su_df2, x ='발생지시군구', y='사망자수')
fig.show()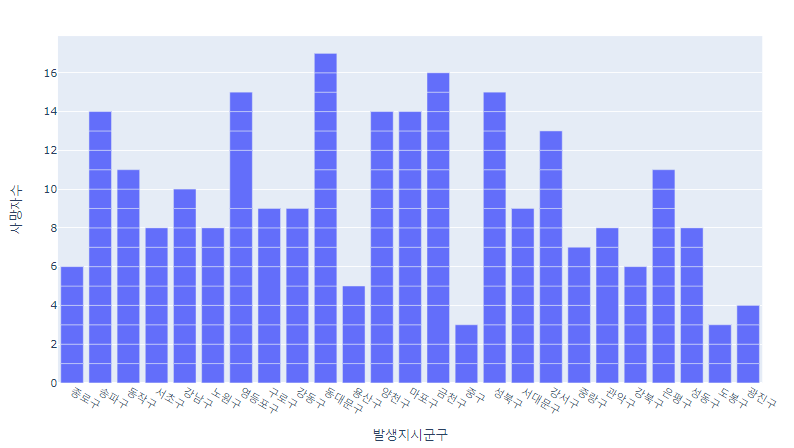
서울 사고 유형별 교통사고 사망자수 현황
# 2019
fig = px.bar(su_df1, x='사망자수', y='사고유형', orientation='h', color='주야')
fig.show()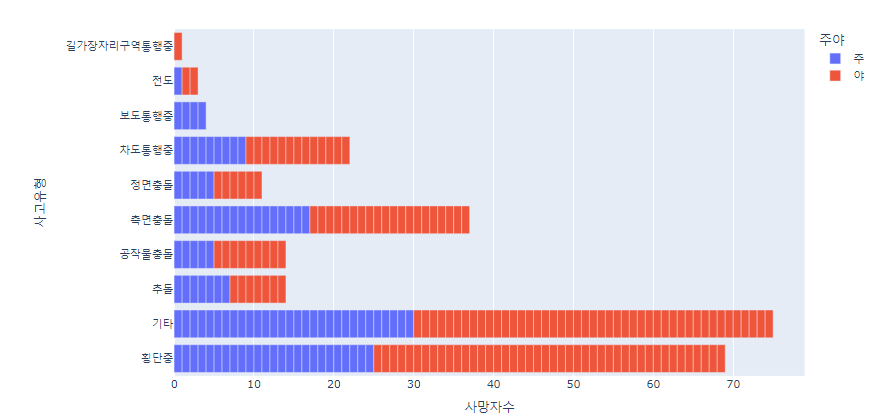
# 2021
fig = px.bar(su_df2, x='사망자수', y='사고유형', orientation='h', color='주야')
fig.show()
서울 데이터 지도 시각화
import folium
su_map = folium.Map(location=[37.5666805,126.9784147])
su_map
#2019
su_df1 = su_df1.astype({'사망자수' : 'float'})
su_df1 = su_df1.astype({'부상자수' : 'float'})
su_df1.info()
#2021
su_df2 = su_df2.astype({'사망자수' : 'float'})
su_df2 = su_df2.astype({'부상자수' : 'float'})
su_df2.info()
# 2019
su_map = folium.Map(location=[37.5666805,126.9784147])
for n in su_df1.index :
c = su_df1['사망자수'][n] + su_df1['부상자수'][n]
folium.CircleMarker([ su_df1['위도'][n], su_df1['경도'][n]], radius = c*10, popup = su_df1['사고유형'][n],
color = 'blue', fill_color='blue').add_to(su_map)
su_map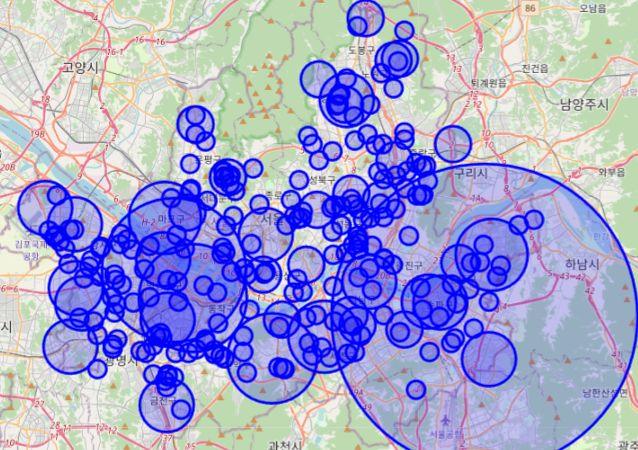
# 2021
su_map = folium.Map(location=[37.5666805,126.9784147])
for n in su_df2.index :
c = su_df2['사망자수'][n] + su_df2['부상자수'][n]
folium.CircleMarker([ su_df2['위도'][n], su_df2['경도'][n]], radius = c*10, popup = su_df2['사고유형'][n],
color = 'blue', fill_color='blue').add_to(su_map)
su_map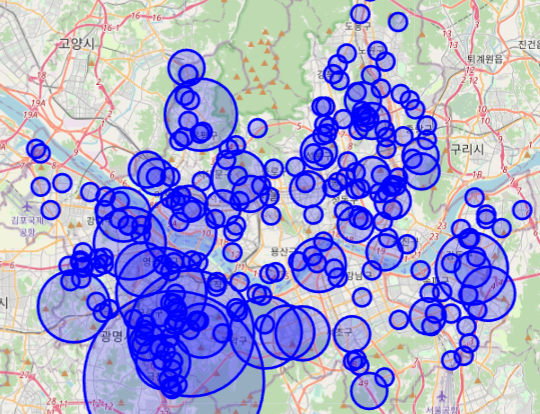
화물차 사고를 비교해보자
# 2019
su_map = folium.Map(location=[37.5666805,126.9784147])
for n in su_df1.index :
c = su_df1['사망자수'][n] + su_df1['부상자수'][n]
if su_df1['가해자_당사자종별'][n] == '화물차':
folium.CircleMarker([ su_df1['위도'][n], su_df1['경도'][n]], radius = c*10, popup = su_df1['사고유형'][n],
color = 'red', fill_color='red').add_to(su_map)
else: pass
su_map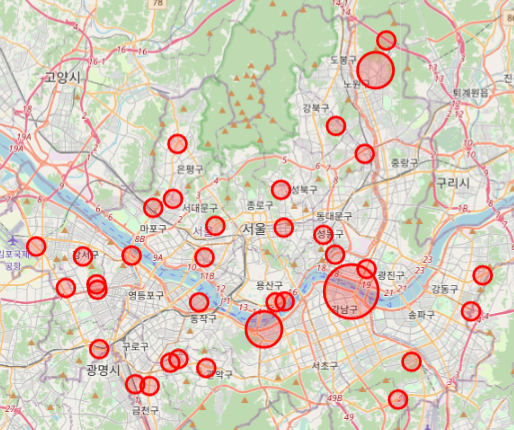
# 2021
su_map = folium.Map(location=[37.5666805,126.9784147])
for n in su_df2.index :
c = su_df2['사망자수'][n] + su_df2['부상자수'][n]
if su_df2['가해자_당사자종별'][n] == '화물차':
folium.CircleMarker([ su_df2['위도'][n], su_df2['경도'][n]], radius = c*10, popup = su_df2['사고유형'][n],
color = 'red', fill_color='red').add_to(su_map)
else: pass
su_map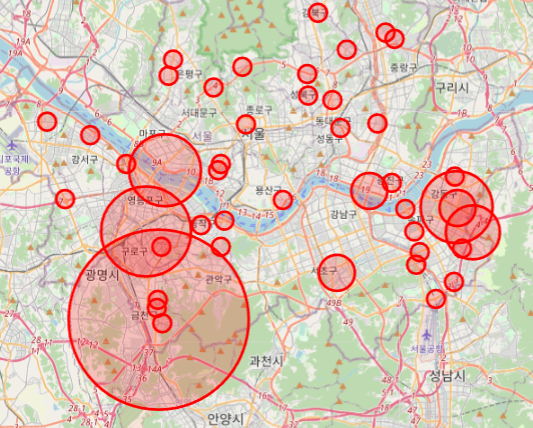
팀원들에게 보낸 설명
2019년 데이터와 2021년 데이터 한번에 한 파일 내에서 확인할 수 있도록 했습니다.
데이터 전처리 과정 자체는 실습시간때 한 것과 동일하고, 2019년, 2021년 모두 동일하다고 생각하시면 될 것 같습니다.
<전체 데이터 분석>
1. scatter 차트를 이용해 2019년 차트와 2021년 차트를 비교
---> 이때, 원의 크기를 사망자수로 지정
2. 시간대별 교통사고 현황을 2019년과 2021년 그래프를 그려 비교
---> 이때, for문과 if문을 사용해서 어느 시간대가 교통사고가 많았는지 확인해주는 코드를 구현했습니다.
혹시나, 제가 아니라 다른분이 발표하실때를 대비해서 코드 설명 적어놓겠습니다
우선, 각 시간대별 횟수를 세주기 위해서 모든 요소가 0으로 초기화된 리스트를 선언해주었으며, 이때 0 ~ 23시로 되어있기 때문에 24개의 요소를 선언했습니다.
이 경우, 시간 자체가 인덱스가 될 수 있어 인덱스는 따로 선언해주지 않았습니다.
첫번째 for문은 df1의 데이터의 모든 행을 확인하기 위해서 사용했고,
두번째 for문은 리스트를 반복해주기 위해서 사용했습니다.
만약, 19년도 데이터프레임의 발생시간이 k 즉, 리스트의 인덱스와 같으면 해당 인덱스에 해당하는 값을 1씩 추가해줍니다.
즉, 19년도 데이터프레임에서 각 시간이 나올 때마다 각 시간을 인덱스로 갖고있는 리스트의 요소를 하나씩 추가해주면서 개수를 센다고 생각해주시면 될 것 같습니다.
3. 지역별 교통사고 현황을 2019년과 2021년 그래프를 그려 비교
---> 이 경우의 for문과 if문도 위의 코드와 동일한 원리로 구현되었다고 생각하시면 될 것 같습니다.
하지만, 이 경우 인덱스가 숫자가 아닌 지역으로 설정되어야 가장 큰 값에 해당하는 지역을 인덱스로 해서 출력할 수 있기 때문에 인덱스에 해당하는 리스트를 하나 더 선언했다고 생각하시면 될 것 같습니다.
또한, 원래는 두 리스트 모두 인덱스로 돌리려고 했지만, 시간 부족으로 그렇게 구현은 하지 못해서 일단 if ~ elif ~ else 문을 사용해서 각 지역에 해당하는 행을 만나면 count해주는 형식으로 구현했습니다.
마지막으로 출력하기 전, 시리즈의 형식으로 리스트를 선언해주었고, index를 해당 도시 명으로 주어서 최고값에 해당하는 인덱스를 출력하면 해당 도시가 나오도록 구현했습니다.
4. 요일별 교통사고 현황을 2019년과 2021년 그래프를 그려 비교
---> 위 지역별 교통사고 현황을 분석할 때 쓰였던 for문과 if문과 동일한 원리로 구현했습니다.
<서울시 분석>
1. 서울시 분석은 시간부족으로 인해 간단한 기초적인 그래프 분석만 진행하였습니다.
2. 첫번째 지도 분석에는 아무런 구분 없이 사고난 곳을 사망자수+부상자수의 반지름을 가진 CircleMarker를 표시하는 시각화를 진행했습니다.
3. 두번째 지도 분석에는 세진님이 진행하셨던, 가해자_당사자종이 화물차에 해당하는 사고만 출력해 2019년과 2021년을 비교했습니다.
팀원들에게 보낸 분석(개인)
분석
1. 시간대별 교통사고
2019년은 19시, 2021년은 18시
1) 뉴스를 찾아봤는데 코로나를 계기로 업무 시공간을 자율적으로 결정하면서 업무 효율에 집중하는 기업이 늘고있다는 것도 이유 중 하나일 것 같습니다.
2. 지역별 교통사고
2019년은 경기, 2021년도 경기
횟수 : 608 -> 525
1) 코로나로 인해서 교통량이 감소하였기 때문일 것 같습니다.
이 부분은 출력을 해봤는데, 거의 대부분의 도시가 감소했습니다. (광주만 그대로였습니다) 증가한 도시가 없는 것으로 봐서는 교통량 감소로 인한 전국적 변화가 아닐까 생각합니다
3. 요일별 교통사고
2019년은 금요일, 2021년은 목요일
1) 교수님께서 말씀하신 회식이 금요일보다는 목요일에 선호하는 직장인이 많아졌다는 것도 이유 중 하나일 것 같습니다.
2) 뉴스를 찾아봤는데 코로나를 계기로 업무 시공간을 자율적으로 결정하면서 업무 효율에 집중하는 기업이 늘고있다는 것도 이유 중 하나일 것 같습니다.
4. 지도 시각화
왜 화물차 사고가 2019년보다 2021년이 더 많을까?
1) 단톡방에서 말씀드렸듯이, 코로나로 인한 택배 서비스의 활성화로 인해서 택배나 배송 등의 유통량이 늘어 화물차의 통행량 역시 함께 증가했고, 이때문에 사고량도 증가한게 아닐까 추측해봤습니다
** 설명 다시 작성하는 것이 애매해서 팀원들에게 보냈던 설명으로 복붙했음.. **
'대외활동 > ABC 지역주도형 청년 취업역량강화 ESG 지원산업' 카테고리의 다른 글
| [ABC 220831 - 12일차] 어울링 크롤링 (0) | 2022.09.02 |
|---|---|
| [ABC 220831 - 12일차] 과제 피드백 (0) | 2022.09.02 |
| [ABC 220831 - 11일차] 4번째 특강 (0) | 2022.08.31 |
| [ABC 220831 - 11일차] 웹 크롤링 (0) | 2022.08.31 |
| [ABC 220830 - 10일차] HTML 기초 (0) | 2022.08.31 |


